- Offer Profile
- The Computational Interaction and Robotics Lab is a research laboratory in the Department of Computer Science at Johns Hopkins University. We are also associated with the NSF Engineering Research Center for Computer-Integrated Surgical Systems and Technology (ERC-CISST) and the Laboratory for Computational Sensing and Robotics (LCSR). We are interested in understanding the problems that involve dynamic, spatial interaction at the intersection of vision, robotics, and human-computer interaction.
MAPS - Manipulating and Perceiving Simultaneously
- The goal of this project is to develop a system,
consisting of a robotic hand equipped with tactile sensors, capable of
autonomously exploring an environment and identifying objects that have been
encountered before, while manipulating the unknown objects as necessary. The
ability to explore an unknown object using solely haptic information
requires expansion of the state of the art both in object recognition and in
manipulation, in addition to the application of simultaneous localization
and mapping techniques to the haptic domain. Our approach focuses first on
the adaptation of feature-based object recognition methods, from the
computer vision domain, to haptic object recognition.
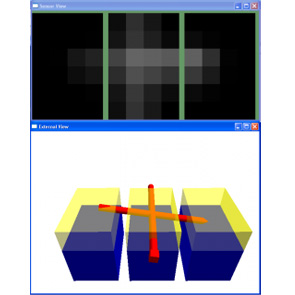
The Schunk Anthropomorphic Hand (SAH), mounted upon the Barrett WAM arm, with tactile sensors from Pressure Profile Systems, is our platform for haptic manipulation, however extensive work is also being conducted in a simulator for tactile sensing that we are developing (shown in a screen-shot below). 
- picture on right courtesy of Schunk
Language of Surgery
- Surgical training and evaluation has traditionally been an interactive and slow process in which interns and junior residents perform operations under the supervision of a faculty surgeon. This method of training lacks any objective means of quantifying and assessing surgical skills. Economic pressures to reduce the cost of training surgeons and national limitations on resident work hours have created a need for efficient methods to supplement traditional training paradigms. While surgical simulators aim to provide such training, they have limited impact as a training tool since they are generally operation specific and cannot be broadly applied. Robot-assisted minimally invasive surgical systems, such as Intuitive Surgical’s da Vinci, introduce new challenges to this paradigm due to its steep learning curve. However, their ability to record quantitative motion and video data opens up the possibility of creating descriptive, mathematical models to recognize and analyze surgical training and performance. These models can then be used to help evaluate and train surgeons, produce quantitative measures of surgical proficiency, automatically annotate surgical recordings, and provide data for a variety of other applications in medical informatics.
Context-Aware Surgical Assistance for Virtual Mentoring
- Minimally invasive surgery (MIS) is a technique
whereby instruments are inserted into the body via small incisions (or in
some cases natural orifices), and surgery is carried out under video
guidance. While presenting great advantages for the patient, MIS presents
numerous challenges for the surgeon due to the restricted field of view
presented by the endoscope, the tool motion constraints imposed by the
insertion point, and the loss of haptic feedback. One means of overcoming
some of these limitations is to present the surgeon with a registered
three-dimensional overlay of information tied to pre-operative or
intraoperative volumetric data. This data can provide guidance and feedback
on the location of subsurface structures not apparent in endoscopic video
data.
Our objective is to develop algorithms for highly capable context-aware surgical assistant (CASA) robotic systems that are able to maintain a dynamically updated model of the surgical field and ongoing surgical procedure for the purposes of assistance, evaluation, and mentoring. Information that must be maintained includes real-time representation of the patient’s anatomy & physiology, the relationship of surgical instruments to the patient’s anatomy, and the progress of the procedure relative to the surgical plan. In the case of telesurgical systems, one key challenge is the real-time fusion of preoperative models and images with stereo video and real-time motion of surgical instruments. Our approach dynamically registers pre-operative volume data to surfaces extracted from video, and thus permits the surgeon to view pre-operative high-resolution CT or MRI or intra-operative ultrasound scans directly on tissue surfaces. By doing so, operative targets and pre-operative plans will become clearly apparent.
We are developing an integrated demonstration of the feasibility of performing such a fusion within the context of a CASA robotic system and we will demonstrate simple capabilities to use the fused information to monitor interactions of the surgical instruments with the target anatomy and detect changes in the anatomy.
Our project is currently targeting minimally invasive surgery using the da Vinci surgical robot. The da Vinci system provides the surgeon with a stereoscopic view of the surgical field. The surgeon operates by moving two master manipulators which are linked to two (or more) patient-side manipulators. Thus, the surgeon is able to use his or her natural 3D hand-eye coordination skills to perform delicate manipulations in extremely confined areas of the body.
For the CASA project, the robotic surgery system presents several advantages. First, it provides stereo (as opposed to the more common monocular) data from the surgical field. Second, through the da Vinci API, we are able to acquire motion data from the master and slave manipulators, thus providing complete information on the motion of the surgical tools. Finally, we are also provided with motion information on the observing camera itself, making it possible to anticipate and compensate for ego-motion.
Algorithms are developed and evaluated on phantom data and data acquired using the Intuitive Surgical da Vinci system. Micro-Surgical Assistant Workstation
- Providing enhanced information and physical abilities
to surgeons
The Micro-Surgical Assistant Workstation is a system which is designed to aid and augment the performance of micro-surgical tasks by a human surgeon. A micro-surgical task is simply a surgical task which is performed on such a small scale that it must be done while looking through a microscope.
There are two main components to the workstation; the first aims to give the surgeon better knowledge about the field of operation, and the second aims to give the surgeon a better ability to execute very precise motions with surgical tools even when working at a microscopic scale.
One example of the first component would be providing the surgeon with information about the surgical environment which would not normally be available, such as overlaying images from another imaging modality (eg. CT, MRI, OCT, Fundus), which would be registered in real time to images captured through the operating microscope.
The current example of the second component is the Steady Hand Robot, which is a cooperative manipulator designed to improve the fine motor control of a surgeon. The surgeon and the robot both hold the same tool; when the surgeon exerts a force on the tool, the robot detects that force, and moves the tool correspondingly. Having the robot in the loop allows us to do force scaling, effectively slowing down the motion of the tool; this allows for more precise positioning than could be done free hand. Additionally, the robot gives greater stability, as a tool can be released by the surgeon and will stay in the same position, rather than falling.
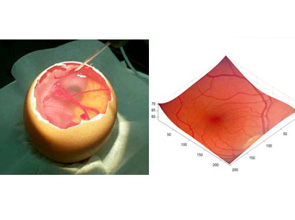
The current model on which the Micro-Surgical Assistant Workstation is being developed and evaluated is a retinal-surgery model, and several retinal surgery tasks have been attempted with the robot. Capsule Endoscopy
- Capsule endoscopy (CE) has recently emerged as a
valuable imaging technology for the gastrointestinal (GI) tract, especially
the small bowel and the esophagus. With this technology, it has become
possible to directly evaluate the gut mucosa of patients with a variety of
conditions, such as obscure gastrointestinal bleeding, Celiac disease and
Crohn's disease.
Although the use of capsule endoscopy is gaining rapidly, the evaluation of capsule endoscopic imagery presents numerous practical challenges. In a typical case, the capsule acquires 50,000 or more images over an eight-hour period. The quality of these images is highly variable due to the uncontrolled motion of the capsule itself as it moves through the GI tract, the complexity of the structures being imaged, and inherent limitations of the disposable imager. In practice, relatively few (often less than 1000) of the study images contain significant diagnostic content. As a result, it is challenging to create an effective, repeatable means for evaluating capsule endoscopic sequences.In this NIH funded effort, we are interested in creating a tool for semi-automated, objective, quantitative assessment of pathologic findings in capsule endoscopic data, and in particular, quantitative assessment of lesions that appear in Crohn's disease of the small bowel. We are developing statistical learning methods for performing lesion classification and assessment in a manner consistent with a trained expert.
To evaluate our methods, we have collected a substantial database of images of Crohn's lesions together with an expert assessment of several attributes indicative of lesion severity. In addition, our database also contains a large number of other GI anomalies seen in CE. Recent publications on reduction of complexity of CE assessment by reducing the number of images that need to be examined by a clinician and statistical methods for assessment appear in the publications page. 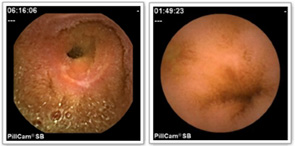
- Sample images from our capsule endoscopy database. From left to right: a severe lesion, normal villi, lesion not related to Crohn's, and a mild Crohn's lesion.
Computer Vision for Sinus Surgery - Registering Endoscopic Video to Preoperative 3D Models
- The focus of this project is to study the problem of registering an endoscopic video sequence to a preoperative CT scan with applications to sinus surgery. The main goal of this project is to be able to accurately track the tip of the endoscope in real-time using vision techniques and thus be able to determine tool tip locations within the sinus passage. The advantages to being able to do real-time visual tracking are quite substaintial as current tool tracking systems for sinus surgery are often cumbersome to use since they can require modification of the tool handles, require additional bulky machinery which occupies valuable operating room floor space and can cost large sums of money which can detract from the budgets for other surgical tools. This project is being persued under a grant from the NIH
Real-time Video Mosaicking with Adaptive Parametrized Warping
- Image registration or alignment for video mosaicing has many research and real applications. Our motivations come primarily from the medical field, and primarily seek to over come fundamental field of view and resolution tradeoffs that occur ubiquitously in endoscopic surgery. There are two general approaches to computing the visual motions between successive images, the critical issue for registration. Direct approaches use all the image pixels available to compute an image-based error, which is then optimized. Complementary approaches are to specifically detect certain image features first then to estimate the corresponding relations between image feature pairs in different camera views. The latter often has the advantage of a larger range of convergence, although at the cost of a prior feature-detection and correspondence stage.
Human Machine Collaborative Systems
- During micro-scale manipulation tasks such as
microsurgery, the human operator performs at the limits of his or her motor
control. The high accuracy required while performing such procedures makes
the task both mentally and physically demanding. As part of the Engineering
Research Center for Computer-Integrated Surgical Systems and Technology (ERC-CISST),
Professor Allison Okamura in Mechanical Engineering and researchers in
Computer Science (Gregory Hager and Russell Taylor) are designing systems
that amplify or assist human physical capabilities when performing tasks
that require learned skills, judgment, and dexterity. We refer to these
systems as Human-Machine Collaborative Systems (HMCS), as they generally
seek to combine human judgment and experience with physical and sensory
augmentation using advanced display and robotic devices to improve the
overall performance (Figure 1).
Human-machine systems offer the operator a direct interaction with the environment through a single robot (Cooperative manipulation) or remotely through multiple robots (Telemanipulation). In addition, the robots can guide the user using "Virtual Fixtures", which are control methods designed to encourage the user to move in certain directions and prevent tool entry into undesired regions. The target applications of HMCS include micro-surgical procedures such as retinal and sinus surgery (Figure 2) and industrial micro-assembly. 
- Figure 1: The JHU Eye Robot, in which the surgeon and robot cooperate to perform retinal surgery, is a Human-Machine Collaborative System.
- Figure 2: The robot guides the human to perform certain motions or stay away from delicate tissues, using reconstructions of the retinal surface.
Motion Compensation in Cardiovascular MR Imaging
- Robust MR imaging of the coronary arteries is challenging due to the complex motion of these arteries induced by both respiratory and cardiac motion. Current approaches have had limited success due to the motion artifacts introduced by the variability in cardiac and respiratory motion during data acquisition. The effects of motion variability can be significantly reduced if the motion of the coronary artery can be estimated and used to guide MR image acquisition. We thus propose a method that involves acquiring high speed low-resolution images in specific orientations, extracting coronary motion to guide the high-resolution MR image acquisition. In order to show the feasibility of the proposed approach, we present and validate a multiple template tracking approach that allows reliable and accurate tracking of the left coronary artery (LCA) in low-resolution realtime MR image sequences in different orientations. We have also demonstrated using MR simulations that accounting for cardiac variability improves overall image quality.
Multi-Modality Retinal Image Registration
- Optical coherance tomography is a non-invasive imaging modality analogous to ultrasound using light rays. Registration of pre-operative OCT images to more familiar and easily available intra-operative fundus images allows precise location of pathologies which might otherwise be invisible, allowing a wider array of interventions.
Vision-Based Human Computer Interaction
- The Visual Interaction Cues (VICs) project is focused
on developing new techniques for vision-based human computer interaction (HCI).
The VICs paradigm is a methodology for vision-based interaction operating on
the fundamental premise that, in general vision-based HCI settings, global
user modeling and tracking are not necessary. For example, when a person
presses the number-keys while making a telephone call, the telephone
maintains no notion of the user. Instead, it only recognizes the action of
pressing a key. In contrast, typical methods for vision-based HCI attempt to
perform global user tracking to model the interaction. In the telephone
example, such methods would require a precise tracker for the articulated
motion of the hand. However, such techniques are computationally expensive,
prone to error and the re-initialization problem, prohibit the inclusion of
an arbitrary number of users, and often require a complex gesture-language
the user must learn. In the VICs paradigm, we make the observation that
analyzing the local region around an interface component (the telephone key,
for example) will yield sufficient information to recognize user actions.
The principled techniques of the VICs paradigm are applicable in general HCI settings as well as advanced simulation and virtual reality. We are actively investigating 2D, 2.5D, and 3D environments; we've developed a new HCI platform called the 4D Touchpad (figure below) where vision-based methods can complement the conventional mouse and keyboard.
In the VICs project, we study both low-level image analysis techniques and high-level gesture language modeling. In low-level image analysis, we use deterministic (color, shape, motion, etc.), machine learning (e.g. neural networks), and dynamic modeling (e.g. Hidden Markov Models) to model the spatio-temporal characteristics of various hand gestures. We have constructed a highlevel language model that integrates a set of low-level gestures into a single, coherent probabilistic framework. In the language model, every low-level gesture is called a Gesture Word, and each complete action is a sequence of these words called a Gesture Sentence 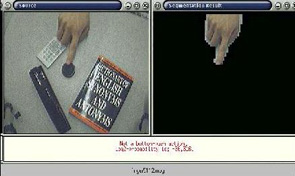
- Adaptive Background Modeling

- Intelligent Buttons

- Left: The 4D Touchpad - A new platform for the
development of next-generation interfaces.
It facilitates unencumbered interaction with an architecture that provides core functionality for general vision-based interfaces.
Right:The new 4DT system. Interaction components are rendered over a flat monitor.
Articulated Object Tracking
- Many objects encountered in the real world can be described as kinematic chains of parts with roughly uniform appearance characteristics. We developed a GPU-accelerated method for tracking such objects in single- or multi-channel (eg, stereo) video streams in diverse domains. The method consists, in brief, of modeling the appearance of the various object parts, then rendering a 3D model of the target object geometry from each view, and measuring the consistency of the resulting image with an appearance class probability map derived from the video images. It's been demonstrated in both surgical and generic settings.

- Sample images, tracking in different domains