- Offer Profile
The Active Vision Group seeks to advance knowledge in computational vision, particularly in the areas of detection and tracking of moving objects, and structure recovery from calibrated and partially calibrated imagery.
The Group works on applications for surveillance, wearable and assistive computing, cognitive vision, augmented reality, human motion analysis, teleoperation, and navigation.
Content Overview
Intelligent Surveillance
- This research integrates the fields of activity
recognition with active sensing. A particular focus lies on a fusion of the
data acquisition process at varying levels of resolution with pro-active
sensing, which includes higher level reasoning.
The topics described next bring together techniques in visual tracking, activity recognition, and intelligent control of pan/tilt/zoom devices in order to be able to reason about visual scenes, infer causal relationships, and detect unusual or otherwise interesting behaviour.Behaviour from Head Pose
The aim of the project is to automatically identify the direction in which people are facing from a distant camera in a surveillance situation to provide input to higher level reasoning systems. The direction in which somebody is facing provides a good estimate of their gaze direction, which can be used to infer familiarity between people or interest in surroundings. It can be seen as closing the gap between a coarse description of humans from a distance and a more detailed motion of limbs, usually obtained from a closer view. The work is partly funded by HERMES, located in work package 3 and 4.Active Scene Exploration
Effective use of resources is an underlying theme of this project. The resources in question are a set of cameras which overlook a common area from varying viewing angles. These cameras are heterogenous and have different parameters for control, e.g. some are static, some are pan, tilt and zoom cameras. Information theoretic measures are used to choose the best surveillance parameters for these cameras, whereas best can be defined by higher level reasoning, or human operators. Currently, the work concentrates on objective functions from information-theory and the use of sensor data fusion techniques to make informed decisions.
As part of the HERMES project, the goal is to establish a perception/action cycle with specific consideration of varying zoom levels. The distributed camera system can be interpreted as an abstract sensor which is content with higher level objectives as input.
The coarsest scale of an agent representation is considered to track agents and note their trajectories, together with other coarse scale features, that will be useful for action and intention recognition. The aim is then to generate behaviour and conceptual descriptions about the agent itself and its relationship with respect to other agents and predefined objects in the scene.Cognitive Computer Vision
Recent work in visual tracking and camera control has looked at the issues involved in activity recognition using parametric and non-parametric belief propagation in Bayesian Networks, and begun to touch on the issues of causality. The current research takes all of these areas forward. The ultimate goal will be to combine these techniques to produce a pan/tilt/zoom camera system, and/or network of cameras, that can allocate attention in an intelligent fashion via an understanding of the scene, inferred automatically from visual data.
The topic is directly related to the EU project HERMES, which is in the exciting and socially relevant area of intelligent visual surveillance. The aim of the research is to develop cameras systems that could be considered to exhibit emergent cognitive behaviour, through developing algorithms and ontologies for understanding of visual scenes.
Cognitive Computer Vision
- Recent work in visual tracking and camera control has
looked at the issues involved in activity recognition using parametric and
non-parametric belief propagation in Bayesian Networks, and begun to touch
on the issues of causality. The current research takes all of these areas
forward. The ultimate goal will be to combine these techniques to produce a
pan/tilt/zoom camera system, and/or network of cameras, that can allocate
attention in an intelligent fashion via an understanding of the scene,
inferred automatically from visual data.
The topic is directly related to the EU project HERMES, which is in the exciting and socially relevant area of intelligent visual surveillance. The aim of the research is to develop cameras systems that could be considered to exhibit emergent cognitive behaviour, through developing algorithms and ontologies for understanding of visual scenes.
In this context, solutions based on fuzzy temporal logic are initially investigated, connecting fuzzy inference to action in an attempt to control pan/tilt/zoom cameras in real-time. Algorithms are to be tested on a network of camera nodes, each one provided with a computer unit for local processing and low-level control of the actuators.
Another important aspect of the project is to investigate new solutions for cognitive vision with an emphasis on intelligent surveillance devices. More specifically, to conduct research into causal reasoning from video, and integrate this with work on activity recognition, visual tracking algorithms, and active control of pan/tilt/zoom devices and other techniques applicable to the broad problem of creating intelligent visual surveillance devices.

Behaviour from Head Pose
- We have developed algorithms to estimate head pose through a novel use of randomised fern classifiers. Instead of measuring the head pose of an image directly, classifiers are used to categorise images into groups according to the head pose. For a head pose estimator to be effective in real-world situations it must be able to cope with different skin and hair colours as well as wide variations in lighting direction, intensity and colour. Most existing classifiers are susceptible to these variations and require examples with different combinations of lighting conditions and skin/hair colour variations in order to make an accurate classification. The approach that we have taken effectively learns a model of the skin and hair colours for each new person that is observed, making it largely invariant to lighting and the individual characteristics of the people in the video. The result is a classifier which works in very low resolution video where heads have a diameter of just 10 pixels.






Avoiding moving outliers in visual SLAM by tracking moving objects
- To work at video rate, the maps that monocular SLAM
builds are bound to be sparse, making them sensitive to the erroneous
inclusion of moving points and to the deletion of valid points through
temporary occlusion. This system provides the parallel implementation of
monoSLAM (monocular simultaneous localization and mapping) with a 3D object
tracker, allowing reasoning about moving objects and occlusion. The SLAM
process provides the object tracker with information to register objects to
the map's frame, and the object tracker allows the marking of features,
either those moving features on moving objects, or those pseudo-features
created by their occluding edges, or those occluded by objects. While a
traditional monoSLAM, assuming a rigid environment, degrades performance,
sometimes terminally, when moving features are included, the combined system
is more robust to dynamic environments. In addition, knowledge that some
static features are occluded rather than unreliable avoids the need to
invoke the somewhat cumbersome process of feature deletion, followed later
perhaps by unnecessary re-initialization, allowing the lifetime of occluded
static features to be extended.
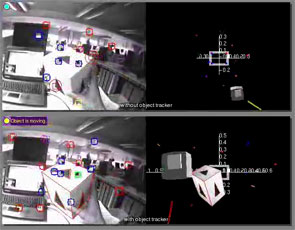
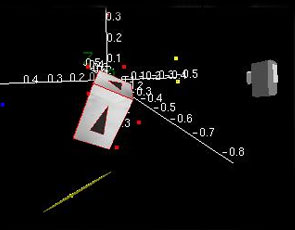
The object tracker is done using a modified version of Harris' RAPiD tracker. The identification and pose initialization are at present done by hand. The videos are presented to verify the recovered geometry and to indicate the impact on camera pose in monoSLAM of including and avoiding moving features. The system without the object tracker gives the incorrect camera's pose due to moving features, but still survives until the end of the video. The system with the object tracker, on the other hand, estimates more correct camera's pose through the image sequences.

Perseus: Tracking Hands for Computer Interaction
- The purpose of this project is to provide a natural
and intuitive way to interact with a computer, by interpreting hand
movements and gestures in real time. A cost effective way of obtaining this
in a non invasive way is to use visual sensing from cameras.
The core of this project is an algorithm that integrates segmentation, 3D pose estimation of a human hand by use of a simplified 3D hand model and a mapping of the pose parameters into a latent space. In order to be able to track in 3D a non rigid articulated object (like a human hand) it must first be able to track in 3D rigid non articulated objects.
The algorithm we have been working on involves adding 3D shape information to a tracking algorithm for 2D rigid object tracking developed inside the Active Vision Group by Charles Bibby and Ian Reid, in their paper, Robust Real-Time Visual Tracking using Pixel-Wise Posteriors. The algorithm treats the image as a bag of pixels (the position of the pixels in the image is considered a random variable), then evolves a level set function by use of pixel-wise posteriors, rather than likelihoods. This approach works in real time on standard hardware. We are working on adding a new prior: the norm of the difference between the rendering of the 3D object model, with properly adjusted pose parameters, and the segmented region of the image, defined by the level set function. This region will then evolve towards the projection of the 3D object.
While the algorithm presented above should work in the case of optimizing towards the pose parameters of a rigid object it will probably be too slow for obtaining the pose of a non rigid, articulated, object. To this end we are looking at using a Gaussian Processes Latent Variable Model mapping between the high dimensional pose space and a low dimensional latent space.
The system uses a custom 3D engine. Traditional 3D rendering engines (like OpenGL or DirectX) lose the relation been 3D points before a transform (rotation, translation and projection) and their resulting 2D projections, during the rendering process. Out engine is able to keep this relation and render a 3D object in wireframe, filled and outline only mode, apply a Scharr filter and compute the distance transform in only a couple of milliseconds. This level of performance is achieved using parallel algorithms developed for the NVIDIA CUDA framework.
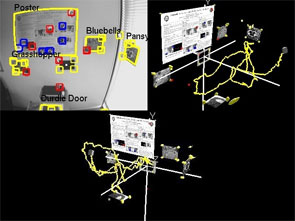
Simultaneous Recognition and Localization for Scene Augmentation
- A system has been developed which combines
single-camera SLAM (Simultaneous Localization and Mapping) with established
methods for feature recognition. Besides using standard salient image
features to build an on-line map of the camera's environment, it is capable
of identifying and localizing known planar objects in the scene, and
incorporating their geometry into the world map. Continued measurement of
these mapped objects improves both the accuracy of estimated maps and the
robustness of the tracking system. In the context of hand-held or wearable
vision, the system's ability to enhance generated maps with known objects
increases the map's value to human operators, and also enables meaningful
automatic annotation of the user's surroundings. The presented solution lies
between the high order enriching of maps such as scene classification, and
the efforts to introduce higher geometric primitives such as lines into
probabilistic maps. The object detection is done using SIFT. A database of
known objects are compared to scene images and when a match is found the 3D
location of the object is calculated using a homography and placed in the
SLAM map with a high level of accuracy.
The video compares the monocular SLAM system running with and without object detection in a spit-screen view. The system without the object detection looses track due to insufficient features, and at this point the video is slowed down to highlight this. The system with the object detection continues and at the end of the video it has successfully detected all five objects and accurately localized them in the world.

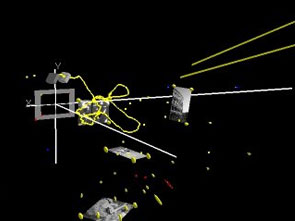
Relocalization of a lost camera in SLAM