Navigation : EXPO21XX > AUTOMATION 21XX >
H05: Universities and Research in Robotics
> Fordham University, New York
Fordham University, New York

Videos
Loading the player ...
- Offer Profile
- The Fordham Robotics & Computer Vision Lab, directed by Dr. Damian Lyons, was founded in the Summer of 2002 . The Lab conducts research in Cognitive Robotics, in team Wayfinding and Navigation and in agile robot platforms.
Product Portfolio
Robotics
- We have developed an approach to tracking targets with complex behavior, leveraging a 3D simulation engine to generate predicted imagery and comparing that against real imagery. In this approach, the salient points in real and imaged images are identified and an affine image transformation that maps the real scene to the synthetic scene is generated. An image difference operation is developed that ensures that the matched points in both images produce a zero difference. In this way, synchronization differences are reduced and content differences enhanced.

- Image of Chair Landmark

- Disparity map
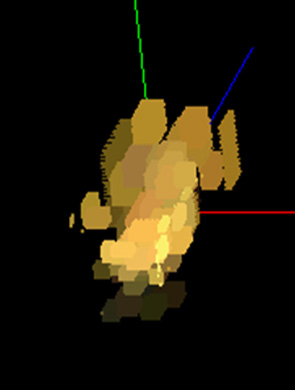
- Terrain Spatiogram









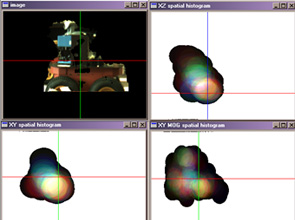
Automated Surveillance
- Sensory Fusion for Multiple Target Tracking
Most existing visual tracking systems do not handle crowded scenes well. Our goal is to develop algorithms that take multiple sensory cues from the video (e.g., target locations, colors, shapes, etc) and fuse this information to robustly track in crowded scenes. We focus on the issue of occluding targets - since this is where a lot of the difficulty in vsiual tracking arises. We use sensory fusion to disambiguate occluding targets. This is a difficult problem, since the process of occlusion gives rise to dramatic and non-linear changes in the feature values. We exploit an approach that determine which cues to use and how to best combine them by looking at the distribution of feature measurement values to candidate targets - the so-called rank-score behavior. Experimentally we have shown that this approach, which we call the Rank and Fuse approach improves on a weighted sum or mahalanobis-sum for fusion.
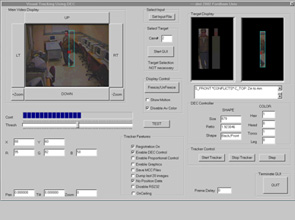
Automated Management of Multiple Camera Resources.
Our goal is to automate the process of switching between multiple cameras when (manually or automatically) tracking a target. A major question in this is to understand the connectivity between camera views. We have developed algorithms and set of software libraries to automatically learn (using a NN) the candidate handoff cameras for each camera in a building. The cameras do not need to have overlapping views, exist and entrances can be anywhere in the field of view, and no map is needed. Future work will include software to periodically update the handoff information to account for camera or building changes.
Combining Recognition with tracking: Discrete-Event Modeling of PTZ targets
Most PTZ tracking systems decide when to pan, tilt or zoom based only on providing the best operator view of the target. While the operator view is clearly an important end-goal for tracking, it is not the only constraint that needs to be acknowledged. A second constraint is that the tracker be able to robustly recognize the target. There is no reason that these two constraints should always agree, and ignoring the second constraint means the operator may get an excellent view of the wrong target! We have developed a discrete-event control approach to modelling the target shape and color in such a way that we can determine when we need to zoom to maintain recognition of the target as well as maintain the operator view. Future work involves extending the discrete-event model to a hybrid model to allow fine control of PTZ.