Navigation : EXPO21XX > AUTOMATION 21XX >
H05: Universities and Research in Robotics
> MIT Media Lab
MIT Media Lab

Videos
Loading the player ...
- Offer Profile
- The Personal Robots Group focuses on developing the principles, techniques, and technologies for personal robots. Cynthia and her students have developed numerous robotic creatures ranging from robotic flower gardens, to embedding robotic technologies into familiar everyday artifacts (e.g., clothing, lamps, desktop computers), to creating highly expressive humanoids --- including the well-known social robot, Leonardo.
Product Portfolio
Research
MDS
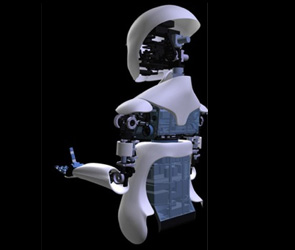
- The MDS Robot is our new robotics platform, which
pushes the limits of existing robotics technology. It synthesizes a novel
combination of: (1) mobility—a wheeled base capable of human-speed movement
in confined or complex environments; (2) dexterity—a five DOF hand and wrist
designed for object manipulation and expressive gesturing; and (3)
sociality—a highly expressive face capable of a wide range of human-style
facial expressions.
The purpose of this platform is to support research and education goals in human-robot interaction, teaming, and social learning. A total of 4 MDS robots will be developed and used to study collaborative robot-robot and human-robot tasks. MIT is responsible for the overall design of the robot, the mobile base is developed by UMASS Amherst, the manipulators developed through collaboration of Xitome Design and Meka Robotics, and the head is built by Xitome Design.
This project is funded in part by an ONR DURIP Award "Mobile, Dexterous, Social Robots to Support Complex Human-Robot Teamwork in Uncertain Environments", Award Number N00014-06-0516 and by the ONR BAA Award "Robust Cognitive Models to Support Peer-to-Peer Human-Robot Teaming", Award Number ONRBAA08-001.
Simulator
As part of our MURI project, our team is building a virtual world simulator for the MDS robot to assist us in developing complex human-robot teaming behaviors.
The simulation companion to our project is based on the USARSim simulator. USARSim builds on Unreal Tournament 2004 and adds various elements (such as robots and environments) for simulating urban search and rescue scenarios. USARSim includes maps that simulate the real test arenas in NIST's Reference Test Facility for Autonomous Mobile Robots for Urban Search and Rescue.
We have added a MDS model to the USARSim that accurately resembles the degrees of freedom of the physical robot. Several of the robot's perceptual systems are simulated as well, including a stereo camera pair in the head and a Hokuyo laser scanner in the base of the robot. The virtual MDS also comes with sound and odometry sensors and can optionally be equipped with an IMU or a GPS.
Our team is also developing tools that visualize the state of the robot (laser readings, localization information on a map, etc.), to allow a remote operator
to control each degree of freedom of the robot and to obtain a live video feed from the cameras.
Our longer-term research touches on peer-to-peer collaboration between humans and robots, automated robot task allocation, and planning for teams of agents under uncertainty.
Participating universities include MIT, University of Washington, Vanderbilt University, UMASS Amherst, and Stanford.
Awards- Best in Show Prize at Siggraph 2008 New Tech Demos.
- Time Magazine "50 best inventions of 2008".

Mobile Manipulator
- The main chassis of the robot is based on the uBot5 mobile manipulator developed by the Laboratory for Perceptual Robotics UMASS Amherst (directed by Rod Grupen). The mobile base is a dynamically balancing platform (akin to a miniature robotic Segway base) capable of traversing indoor environments at human walking speed. On the MDS robot, a third wheel has been added to the base to provide stability due to the addition of the head and arm components.

Forearm, Wrists & Hands
- The 5 degree of freedom lower arm and hands are developed by Meka, Inc. with MIT. The lower arm has forearm roll and wrist flexion. Each hand has three fingers and an opposable thumb --- the thumb and index finger are controlled independently and the remaining two fingers are coupled. A slip clutch in the wrist and shape deposition manufacturing techniques for the fingers were used to make the system ruggedized to falls and collisions. The fingers compliantly close around an object when flexed, allowing for simple gripping and hand gestures.
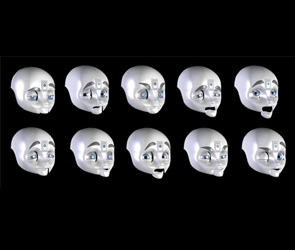
Head & Face
- The expressive head and face are designed by Xitome
Design with MIT. The neck mechanism has 4 DoFs to support a lower bending at
the base of the neck as well as pan-tilt-yaw of the head. The head can move
at human-like speeds to support human head gestures such as nodding,
shaking, and orienting.
The 15 DoF face has several facial features to support a diverse range of facial expressions including gaze, eyebrows, eyelids and an articulate mandible for expressive posturing. Perceptual inputs include a color CCD camera in each eye, an indoor Active 3D IR camera in the head, four microphones to support sound localization, a wearable microphone for speech. A speaker supports speech synthesis.

Social Learning in Physical and Virtual Worlds
- Personal robots are an emerging technology with the potential to have a
significant positive impact across broad applications in the public sector
including eldercare, healthcare, education, and beyond. Given the richness
and complexity of human life, it is widely recognized that personal robots
must be able to adapt to and learn within the human environment from
ordinary citizens over the long term. Although tremendous advances have been
made in machine learning theories and techniques, existing frameworks do not
adequately consider the human factors involved in developing robots that
learn from people who lack particular technical expertise but bring a
lifetime of experience in learning socially with others. We refer to this
area of inquiry as Socially Situated Robot Learning (SSRL).
This work is motivated by our desire to develop social robots that can successfully learn what matters to the average citizen from the kinds of interactions that people naturally offer and over the long-term.
Leonardo
- This project is a collaboration with the world famous
Stan Winston Studio. It combines the studio's artistry and expertise in
creating compelling animatronic characters with state of the art research in
socially intelligent robots. We have christened this new character
collaboration with a name that embodies art, science and invention. Hence,
the name "Leonardo" -- namesake of Leonardo DaVinci, the Renaissance
scientist, inventor and artist.
Indeed, Leonardo is the Stradivarius of expressive robots 
Body
- Robot Mechanics
Leonardo has 69 degrees of freedom --- 32 of those are in the face alone. As a result, Leonardo is capable of near-human facial expression (constrained by its creature-like appearance). Although highly articulated, Leonardo is not designed to walk. Instead, its degrees of freedom were selected for their expressive and communicative functions.Robot Aesthetics
Unlike the vast majority of autonomous robots today, Leonardo has an organic appearance. It is a fanciful creature, clearly not trying to mimic any living creature today.

Vision
- Learning Faces
We have developed a real-time face recognition system for Leonardo that can be trained on the fly via a simple social interaction with the robot.Visual Tracking
A necessary sensory aptitude for a sociable robot is to know where people are and what they are doing. Hence, our sociable robot needs to be able to monitor humans in the environment and interpret their activities, such as gesture-based communication.
The robot must also understand aspects about the inanimate environment as well, such as how its toys behave as it plays with them. An important sensory modality for facilitating these kinds of observations is vision.

Skin
- Sensate Skin
Giving the robot a sense of touch will be useful for detecting contact with objects, sensing unexpected collisions, as well as knowing when it is touching its own body. Other important tactile attributes relate to affective content---whether it is pleasure from a hug, a ticking gesture, or pain from someone grabbing the robot's arm too hard, to name a few.
The goal of this project is to develop a synthetic skin capable of detecting temperature, proximity, and pressure with acceptable resolution over the entire body, while still retaining the look and feel of its organic counterpart. Toward this end, we are experimenting with layering silicone materials (such as those used for make-up effects in special effects industry) over force sensitive resistors (FSR), quantum tunneling composites (QTC), temperature sensors, and capacitive sensing technologies.

Social Learning
- Rather than requiring people to learn a new form of
communication to interact with robots or to teach them, our research
concerns developing robots that can learn from natural human interaction in
human environments.
We are exploring multiple forms of social learning, as well as empirically investigating how people teach robots. Sometimes we leverage on-line game characters to study how many people interact with our learning systems -- more than we could bring into our lab (see Sophie and MDS).
In contrast to many statistical learning approaches that require hundreds or thousands of trials or labeled examples to train the system, our goal is for robots to quickly learn new skills and tasks from natural human instruction and few demonstrations (see Learning by Tutelage). We have found that this process is best modeled as a collaboration between teacher and learner where the teacher guides the robot's exploration, and the robot provides feedback to shape this guidance. This has proven to accelerate the robot's learning process and improve its generalization ability.

Teamwork
- Using joint intention theory as our theoretical
framework, our approach integrates learning and collaboration through a
goal-based task structure. In any collaboration, agents work together as a
team to solve a common problem. Team members share a goal and a common plan
of execution (Grosz 1996). Bratman's analysis of Shared Cooperative Activity
(SCA) introduces the idea of meshing singular sub-plans into a joint
activity. In our work, we generalize this concept to a process of
dynamically meshing sub-plans between human and robot.

Social Cognition
- Social Cognition Socially intelligent robots need to
understand “people as people.” Whereas research with modern autonomous
robots has largely focused on their ability to interact with inanimate
objects whose behavior is governed by the laws of physics (objects to be
manipulated, navigated around, etc.), socially intelligent robots must
understand and interact with animate entities (e.g. people, animals, and
other social robots) whose behavior is governed by having a mind and body.
How might we endow robots with sophisticated social skills and social
understanding of others?
Coupled minds in coupled bodies is a powerful force on human social intelligence and its development. Minds are in bodies with a particular morphological structure. A body’s momentary disposition in space reflects and projects to others the internal state of the system that generated those bodily gestures. Correlations emerging from coupled like bodies with like internal cognitive systems can create --- through the body’s external behaviors – higher order correlations that may lead to inferences about the internal states of self and other.
Other Projects

Public Anemone
- Inspired by primitive life, Public Anemone is a robotic creature with an organic appearance and natural quality of movement. By day, Public Anemone is awake and interacts with the waterfall, pond, and other aspects of its surroundings. It interacts with the audience by orienting to their movements using a stereo machine vision system. But if you get too close, it recoils like a rattlesnake.

OperaBots
- The Operobot project is a system which allows the precise control of a group of omnidirectional mobile robots in real time based on a 3D animation. The current system, which controls the position and brightness of three cube shaped robots, is a proof of concept for what will ultimately be a large scale component of an opera entitled Death and the Powers.

AUR
- AUR is a robotic desk lamp, a collaborative lighting assistant. It's a non-anthropomorphic robotic platform, demonstrating human-robot interaction that happens seamlessly, in the background, illuminating the right thing at the right time. We envision robotic lamps to play a role in future operating rooms, mechanic workshops, and anywhere where an extra hand holding a light is called for.

Huggable™
- The Huggable™ is a new type of robotic companion being
developed at the MIT Media Lab for healthcare, education, and social
communication applications. The Huggable™ designed to be much more than a
fun interactive robotic companion. It is designed to function as a team
member that is an essential member of a triadic interaction. Therefore, the
Huggable™ is not designed to replace any particular person in a social
network, but rather to enhance that human social network.
We are currently working with various Media Lab sponsors to create a series of Huggables for real-world applications and trials. We are also working with Microsoft Research, using Microsoft Robotic Studio to develop the communication avatar implementation.
The early technical development of the Huggable™ was supported in part by a Microsoft iCampus grant.

Cyberflora
- In April of 2003, we debued our Cyberflora installation
as part of the National Design Triennial, hosted by the Cooper-Hewitt
National Design Museum in New York City.
This robotic flower garden is comprised of four species of cyberflora. Each combines animal-like behavior and flower-like characteristics into a robotic instantiation that senses and responds to people in a life-like and distinct manner.
A soft melody serves as the garden's musical aroma that subtly changes as people interact with the flowers.
Delicate and graceful, Cyberflora communicates a future vision of robots that shall intrigue us intellectually and touch us emotionally. The installation explores a style of human-robot interaciton that is fluid, dynamic, and harmonious.

RoCo
- We are developing RoCo, a novel robotic computer designed with the ability to move its monitor in subtly expressive ways that respond to and encourage its user's own postural movement. The design of RoCo is inspired by a series of Human Robot Interaction studies that showed that people frequently mirror the posture of a socially expressive robot when engaged in a social interaction. It is interesting to consider whether a more computer-looking robot with the capability to adjust its "posture" can elicit similar postural mirroring effects during interaction. One potential benefit of introducing increased postural movement into computer use is reduced back pain, where physical movement is recognized as one of the key preventative measures.

Interactive Robot Theater
- The Terrarium is an intelligent stage featuring the Public Anemone. It consists of interactive, autonomous robot performers with natural and expressive motion that combines techniques from animation and robot control. The stage contains real-time, stereo vision that tracks multiple features on multiple people.

Autom
- Human-robot interaction is now well enough understood to allow us to build useful sociable robot systems that can function outside of the laboratory. This is the first project to develop and deploy a sociable robot system to investigate long-term human-robot interaction in people's homes in the context of helping people with their behavior change goals (see research page). Specifically, the sociable robot system is designed assist people who are trying to lose or maintain weight. We selected this application domain because it supports a long-term study where the creation of such a system might make a practical difference. To develop this application, we collaborated with Dr. Caroline Apovian at The Nutrition and Weight Management Center at Boston Medical Center.

TIKL
- Robotic Clothing for Tactile Interaction for
Kinesthetic Learning
People in physical rehabilitation, those with improper posture, and those wanting dance lessons all face a similar task – namely, motor learning. Most people benefit from a teacher who can give real-time feedback through a variety of channels: auditory (high level behavioral instructions), visual (by demonstrating the motion themselves), and tactile (by physically guiding the student). Although tactile feedback presents the most direct form of motor information, it is the most difficult for a teacher to give, especially while performing a task themselves.
This research proposes an extension to the human teacher – a robotic wearable suit that analyzes the target movement (e.g., performed by the teacher) and applies real-time corrective vibrotactile feedback to the student’s body, simultaneously over multiple joints.

Embedded Multi-Axis Controller
- Exploring human-robot interaction requires constructing
increasingly versatile and sophisticated robots. Commercial motor-driver and
motion-controller packages are designed with a completely different
application in mind (specifically industrial robots with relatively small
numbers of relatively powerful motors) and do not adapt well to complex
interactive robots with a very large number of small motors controlling
things like facial features. Leonardo, for instance, includes sixty-some
motors in an extremely small volume. An enormous rack of industrial motion
controllers would not be a practical means of controlling the robot; an
embedded solution designed for this sort of application is required.
We have developed a motor control system to address the specific needs of many-axis interactive robots. It is based on a modular colletion of motor control hardware which is capable of driving a very large number of motors in a very small volume. Both 8-axis and 16-axis control packages have been developed.

MeBot
- Talking by cell phone is becoming truly ubiquitous.
However, phone conversations are not nearly as rich or engaging as talking
to face-to-face. People send numerous non-verbal signals and cues that play
an important role in face-to-face conversation but are lost in phone
conversation. This is unfortunate as these non-verbal cues play an important
role in conveying deeper meanings and attitudes. For instance, group
collaboration or interactive demonstrations would be cumbersome if
everything has to be described through language alone.
What if cell phone communication was more richly embodied? Imagine if you could wander around the same physical space as the person you called, look at different people you are sharing a conversation with, and point at objects shared in that space, while still conveying your remote presence through video of your face and the sound of your voice.
The MeBot is designed to add new non-verbal, physically co-present dimensionality to the use of cellular phones through robot-mediated communication. Think of the MeBot as a robotic accessory for your cell phone – a sort of robot exoskeleton. Say you call your friend via cell phone, she answers and places her phone in a MeBot body. Now, you are a mini-me robot that you remotely operate through your own cell phone!

Tofu
- TOFU is a project to explore new ways of robotic social expression by leveraging techniques that have been used in 2d animation for decades. Disney Animation Studios pioneered animation tools such as "squash and stretch" and "secondary motion" in the 50's. Such techniques have since been used widely by animators, but are not commonly used to design robots. TOFU, who is named after the squashing and stretching food product, can also squash and stretch. Clever use of compliant materials and elastic coupling, provide an actuation method that is vibrant yet robust. Instead of using eyes actuated by motors, TOFU uses inexpensive OLED displays, which offer highly dynamic and lifelike motion.

Novel Actuators
- To date, the industries that have been the driving forces
of actuator technologies have demanded actuators that are precise,
power-dense, fast, small, and cheap.
We face new motivations for actuator design: life-like fluid motion, quiet, continuous control, and compelling, safe and meaningful tactile interactions. To these ends, we are developing actuators that capitalize on certain prior developments, while improving upon them to better suit interactive robot demands. Specifically, we are sacrificing high precision for smoothness and quality of motion, while achieving power and torque densities that are suitable for driving mobile robots.
The goal of this project is to create voice coil-type electromagnetic actuators, with integrated position, velocity and force sensing means. Voice coils are silent, have only one moving part, are naturally smooth and linear, are very robust, have reasonable force and power densities, and are relatively inexpensive.
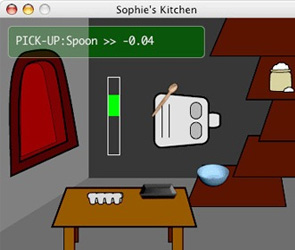
Sophie & Teachable Characters
- As robots become a mass consumer product, they will need
to learn new skills by interacting with typical human users. However, the
design of machines that learn by interacting with ordinary people is a
relatively neglected topic in machine learning. To address this, we advocate
a systems approach that integrates machine learning into a Human-Robot
Interaction (HRI) framework.
Our first goal is to understand the nature of the teacher's input to adequately support how people want to teach.
Our second goal is to then incorporate these insights into standard machine learning frameworks to improve a robot's learning performance.
To contribute to each of these goals, we use a computer game framework to log and analyze interactive training sessions that human teachers have with a Reinforcement Learning (RL) agent -- called Sophie.

Symon & Fluent Teamwork
- Two people repeatedly performing an activity together
naturally converge to a high level of coordination, resulting in a fluent
meshing of their actions. In contrast, human-robot interaction is often
structured in a rigid stop-and-go fashion. Aiming to design robots that are
capable peers in human environments, we wish to attain a more fluent meshing
of human and machine activity.
While the existence and complexity of joint action has been acknowledged for decades, the cognitive mechanisms underlying it have only received sparse attention, predominantly over the last few years (e.g., Sebanz et. al., 2006). Among other factors, successful coordinated action has been linked to the formation of expectations of each partner's actions by the other, and the subsequent acting on these expectations. We argue that the same holds for collaborative robots --- if they are to go beyond stop-and-go interaction, robots must take into account not only past events and current perceived state, but also expectations of their human collaborators.