Oxford Brookes University


- Offer Profile
- The Computer Vision group
in the Department of Computing was formed in 2005 and is led by Professor
Philip Torr. It comprises around 15-18 people.
The aim of the group is to engage in state of the art research into the mathematical theory of computer vision and artificial intelligence, but to keep the mathematical research relevant to the needs of society. Members of the group have won major awards in all the main conferences in the field including the International Conference on Computer Vision (ICCV), CVPR, ECCV, BMVC, NIPs as well as various thesis awards for the students, and industrial awards such as best Knowledge Transfer Partnership.
Product Portfolio
Oxford Brookes Vision Group
- The applications come in many forms, and we are involved with several major companies and organizations. With Sony we are working on human computer interaction (via a camera, the "EyeToy") for the Play Stations 2 and 3, with Sharp we have worked on generation of content for 3D displays, with Oxford Metrics Group we are working on computer understanding of films (e.g. what is the shape of objects in the scene etc) in order to make better special effects, we also work on motion capture of humans (and animals) in order to drive computer generated avatars, with Yotta PlC we are working on automated understanding of road scenes. We work on medical image analysis and on surveillence. We also do collaborative work with Microsoft Research, London, Cambridge and Oxford Universities.
Projects

Human Instance Segmentation from Video using Detector-based Conditional Random Fields
- In this work, we propose a method for instance based human segmentation in images and videos, extending the recent detector-based conditional random field model of Ladicky et.al. Instance based human segmentation involves pixel level labeling of an image, partitioning it into distinct human instances and background. To achieve our goal, we add three new components to their framework. First, we include human partsbased detection potentials to take advantage of the structure present in human instances. Further, in order to generate a consistent segmentation from different human parts, we incorporate shape prior information, which biases the segmentation to characteristic overall human shapes. Also, we enhance the representative power of the energy function by adopting exemplar instance based matching terms, which helps our method to adapt easily to different human sizes and poses. Finally, we extensively evaluate our proposed method on the Buffy dataset with our new segmented ground truth images, and show a substantial improvement over existing CRF methods.

Computer Games
- This proposal concerns research into vision algorithms that might be useful for real world commercial games. Sony Entertainment Europe are an ideal partner in this enterprise as they have pioneered this form of human/machine interaction in the games industry, with the launch of the EyeToy, and continue to be the lead player.

Randomized Trees for Human Pose Detection
- We address human pose recognition from video sequences by formulating it as a classification problem. Our main contribution is a pose detection algorithm based on random forests. Our proposed approach gives promising results with both fixed and moving cameras.

Creation of Content for 3D Displays
- 3D display technology has the potential to be the most important display innovation since the introduction of colour. Evidence that this move to 3D imminent is provided by the recent introduction of a UK developed commercial 3D display on Sharp's Actius range of laptops. The major problem standing in the way is a shortage of 3D content. This research aims to address this problem by developing basic science in the area of 3D content generation in collaboration with Sharp Laboratories Europe.

VideoTrace
- VideoTrace is a system for interactively generating realistic 3D models of objects from video models that might be inserted into a video game, a simulation environment, or another video sequence. The user interacts with VideoTrace by tracing the shape of the object to be modelled over one or more frames of the video. By interpreting the sketch drawn by the user in light of 3D information obtained from vision techniques, a small number of simple 2D interactions can be used to generate a realistic 3D model. Each of the sketching operations in VideoTrace provides an intuitive and powerful means of modelling shape from video, and executes quickly enough to be used interactively. Immediate feedback allows the user to model rapidly those parts of the scene which are of interest and to the level of detail required. The combination of automated and manual reconstruction allows VideoTrace to model parts of the scene not visible, and to succeed in cases where purely automated approaches would fail. VideoTrace has been featured across much of the internet (slashdot, etc) and a spinout company is planned.
Analysis of Human Motion
- In collaboration with world leading motion capture company Vicon, we are exploring new methods for markerless motion capture e.g. inferring from video alone the pose of a person. Vicon's marker based technology is used through out the film industry. Work from Oxford Brookes has recently been licensed by Vicon for inclusion in forth coming products.

Combined Tracking and Object Recognition: Tracking Hands
- Tracking hands in videos is a tough problem because of high dimensionality, that is, the hand can be in one of a huge number of different configurations. By contrast to previous approached based on particle filtering, we are working with colleagues at Cambridge University on a new approach that combines object recognition and tracking in a principled manner.

Analysis of Surveillance Videos
- This project is concerned with the detection of people and vehicles and their activities from videos. This research builds on previous work involving activity recognition and multi-body tracking from motion flow information, and relies on the development of new methods for human detection.
Combinatorial Optimization for Vision
- We are actively developing new combinatorial optimization algorithms for vision. These algorithms include improvements to belief propagation and more efficient ways of performing graph cuts, with applications in dense stereo, segmentation, image editing and motion capture.
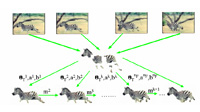
Learning Layered Pictorial Structures
- We learn a generative part-based model of an object given a video by dividing it into rigidly moving components. We develop a novel optic flow algorithm which provides us with the motion vectors of each point in all frames of the video. These motion vectors allow us to cluster rigidly moving points to obtain an initial estimate of the parts. The initial estimate is refined by relabelling the surrounding points of each part using graph cuts such that the energy of the model is minimized.

New View Synthesis: Stereo Views from Video
- With Sharp we are exploring ways of producing a stereo pair for each frame in a video sequence, enabling the conversion of 2D movies to 3D and with it the creation of content for Sharp's new 3D LCDs. While similar to standard new view synthesis, we are solving the additional problems of narrow baseline camera motion, independently moving objects and synthesising non-visible surfaces.

Object Recognition - Face Detection
- We developed face detection methods based on cascaded classifiers, predating Viola but perhaps not as a fast as the features we used were not as efficient as Haar wavelet. Cascades and tree based cascades have been a feature of our work for object recognition and tracking.

Object Recognition and Segmentation
- We solve the problem of object recognition using a part-based model.Given an image, multiple hypotheses are generated for the positionof each part of the object. A Markov random field is defined overthe parts of the object where each state represents a putativeposition of the part. The MAP estimate of the location of the objectis obtained using belief propagation. Once the parts of the objectare localized, we use graph cuts to obtain the segmentation of theobject by constraining the shape of the segmentation to be object-like.
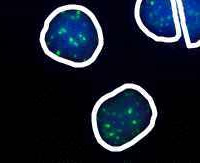
Quantification of Genetic Information for Chromosome images
- The SAFE Network is a new European-wide research project with 54 partners in 12 countries, funded at 14 million euro over the next 5 years. The aim of the project is to develop new methods for non-invasive prenatal detection of genetic disease. We are leading the image processing and cytomety research on this project. We are developing new methods for the automation of tests involving fetal cell markers in the maternal circulation. These methods include automated image analysis and pattern classification, and they make use of the latest developments in robust statistics.
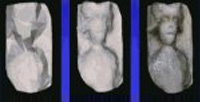
Volumetric Graph Cuts (VOGCUTS)
- Recovery of structure from images is a long established problem in vision. We have been exploring some new techniques based on fitting meshes and then using graph cuts in 3D to model the relief.
Dynamic Measurement of Back Surface Topography
- Curvature of the spine is one of the major skeletal diseases in growing children where in the majority of cases the cause is unknown and the only indicators of the condition are changes in the surface shape of the back over time. The dynamic posture of the patient can mask the underlying deformity so we are using modified motion capture equipment to attempt to improve the reliability of the shape measurement.

Single View Reconstruction
- We are developing a system for recovering approximate 3D from single views of the scene. We are exploring this reconstruction problem in light of the recent developments in combinatorial optimization techniques for vision problems.