Columbia University

Videos
Loading the player ...
- Offer Profile
- Columbia University Robotics Group is a group of researcher consist of student researcher and distinguished professors from Computer Science Department of Columbia University. These past years many projects have been successfully being introduced by them and helped in many fields especially in robotic grasping, 3-D vision & modeling, and medical robotics.
Product Portfolio
Assistive Robotics: Brain Computer Interfaces for Grasping
- Assistive Robotics for Grasping and Manipulation using
Novel Brain Computer Interfaces
This is a collaborative proposal (with UC Davis) which is aimed at making concrete some of the major goals of Assistive Robotics. A team of experts has been brought together from the fields of signal processing and control (PI Sanjay Joshi), robotic grasping (PI Peter Allen), and rehabilitative medicine (PI Joel Stein) to create a field-deployable assistive robotic system that will allow severely disabled patients to control a robot arm/hand system to perform complex grasping and manipulation tasks using novel Brain Muscle Computer Interfaces (BMCI). Further, the intent of this effort is not just technology-driven, but is also driven by clear and necessary clinical needs, and will be evaluated on how well it meets these clinical requirements. Validation will be performed at the Department of Regenerative and Rehabilitation Medicine at Columbia University on a diverse set of disabled users who will provide important feedback on the technology being developed, and this feedback will be used to iterate on the system design and implementation. 
A user of our BCI interface controlling the system.
- The subject wears an Emotiv Epoc EEG headset which is used to detect facial gestures that control the system. A point cloud is obtained by a Microsoft Kinect and used to detect the identity and position of the target object. Then the user uses the EEG headset to guide a grasp planning interface to find a good grasp for the object, and the grasp is sent to our robotic grasping platform for execution.
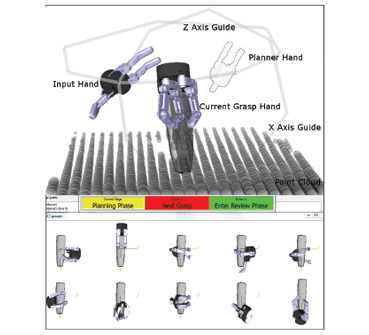
The user interface for the semi-autonomous grasp.
- The user interface is comprised of three windows: The main window containing three labeled robot hands and the target object with the aligned point cloud, the pipeline guide window containing hints for the user to guide their interaction with each phase of the planner, and the grasp view window containing rendering of the ten best grasps found by the planner thus far. The point cloud allows the user to visualize the fit of the model and act accordingly.
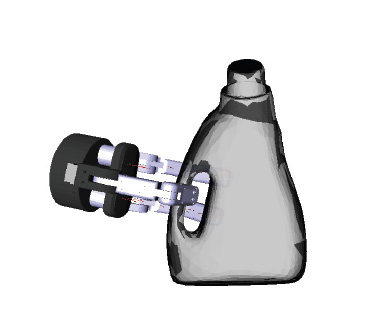
Experimental Subject
- This handle grasp for the all bottle is not a force closure grasp, but when chosen by the subjects in our experiments it succeeded 100% of the time. Adding a grasp database allows such semantically relevant grasps to be used in our system.
In-Vivo Surgical Imaging System
- In-Vivo Pan/Tilt Endoscope with Integrated Light
Source
Endoscopic imaging is still dominated by the paradigm of pushing long sticks into small openings. This approach has a number of limitations for minimal access surgery, such as narrow angle imaging, limited workspace, counterintuitive motions and additional incisions for the endoscpic instruments. Our intent is to go beyond this paradigm, and remotize sensors and effectors directly into the body cavity. To this end, we have developed a prototype of a novel insertable pan/tilt endoscopic camera with an integrated light source. The package has a size of 110 mm in length and 10 mm in diameter and can be inserted into the abdomen through a standard trocar and then anchored onto the abdominal wall, leaving the incision port open for access. The camera package contains three parts: an imaging module, an illumination module, and a pan/tilt motion platform. The imaging module includes a lens and CCD imaging sensor. The illumination module attaches to the imaging module and has an array of LED light sources. The pan/tilt platform provides the imaging module with pan of 120 degrees and tilt motion of 90 degrees using small servo motors. A fixing mechanism is designed to hold the device in the cavity. A standard joy stick can be used to control the motion of the camera in a natural way. The design allows for multiple camera packages to be inserted through a single incision as well. 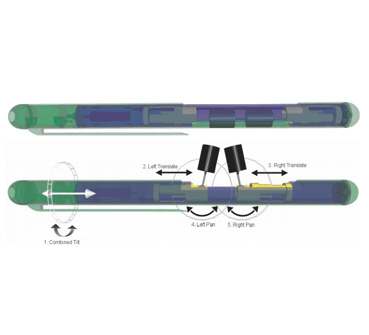
- Design of Prototype I: five-DOF insertable camera
device.
Top: device with cameras retracted.
Bottom: device with cameras extracted.

- Some of the task (e.g: surturing, image training, required motions over great distances) that use the Prototype
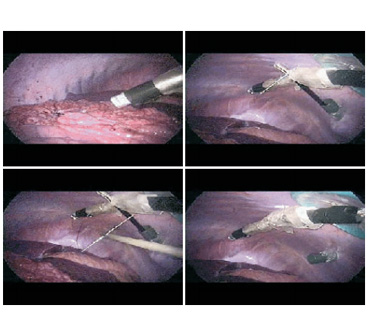
- Prototype being used in surgical task.
Upper left: image of Prototype II camera (without zoom axis) being inserted into the abdominal cavity.
Upper right:insertion of needle used to attach device to abdomen. Lower left: needle looping around device for attachment.
Lower right: device firmly attached to abdominal wall.
Computational Tools for Modeling, Visualizing and Analyzing Historic and Archaeological Sites
- National Science Foundation Grant IIS-0121239
This has been a 6 year project, begun in September 2001, and work related to the project is still ongoing. We had a number of broad research goals in this research project:- Developing new methods of creating complex, three-dimensional, photo-realistic, interactive models of large historical and archaeological sites.
- Developing a system to create a new class of information visualization systems that integrate three-dimensional models, two dimensional images, text, and other web-based resources to annotate the physical environment. This system will support scientists in the field, as well as facilitate on-site interpretation and distance learning.
- Developing new database technology to catalogue and access a site's structures, artifacts, objects, and their context. This will significantly improve a user's ability to query and analyze a site's information.
- Developing methods and resources that will permit teachers and students to access the model and associated information over the Internet and to use it both in the classroom and at home. The goal is to allow flexible access on a variety of educational levels to a mass of emerging scientific and historic data to show how discovery and change are a part of both scientific and interpretive dynamic processes.
Activities:
France: Modeling the Cathedral of Ste. Pierre, Beauvais, France
New York: Modeling Cathedral of St. John The Divine
Sicily: Modeling Acropolis at Mt. Palazzo, Sicily
South Africa: Modeling Thulamela
Governors Island: Fort Jay Model
Egypt: Excavations at Amheida, Egypt ; Panorama Modeling of Egyptian Site
Archaeological Visualization: Collaborative Visualization of an Archaeological Excavation; Cross-Dimensional Gestural Interaction
Databases for Archaeology: ArchQuery Columbia Faceted Database Query Engine
The AVENUE Project
- AVENUE stands for
Autonomous Vehicle for Exploration and Navigation in Urban Environments.
The project targets the automation of the urban site modeling process. The main goal is to build not only realistically looking but also geometrically accurate and photometrically correct models of complex outdoor urban environments. These environments are typified by large 3-D structures that encompass a wide range of geometric shapes and a very large scope of photometric properties.
The models are needed in a variety of applications, such as city planning, urban design, historical preservation and archaeology, fire and police planning, military applications, virtual and augmented reality, geographic information systems and many others. Currently, such models are typically created by hand which is extremely slow and error prone. AVENUE addresses these problems by building a mobile system that will autonomously navigate around a site and create a model with minimum human interaction, if any.
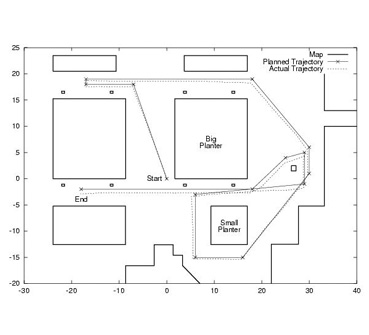
The task of the mobile robot is to go to desired locations and acquire requested 3-D scans and images of selected buildings. The locations are determined by the sensor planning (a.k.a view planning) system and are used by the path planning system to generate reliable trajectories which the robot then follows. When the robot arrives at the target location, it uses the sensors to acquire the scans and images and forwards them to the modeling system. The modeling system registers and incorporates the new data into the existing partial model of the site (which in the beginning could be empty). After that, the view planning system decides upon the next best data acquisition location and the above steps repeat. The process starts from a certain location and gradually expands the area it covers until a complete model of the site is obtained. 
Mobile Platform
- The robot that we use is an ATRV-2 model manufactured by
Real World Interface, Inc, which is now iRobot. It has a maximum payload of
100kg (220lbs) and we are trying to make a good use of that. To the twelve
sonars that come with the robot we have added numerous additional sensors
and periphery:
- a pan-tilt unit holding a color CCD camera for navigation and image acquisition
- a Cyrax laser range scanner with extremely high quality and 100m operating range.
- a GPS receiver working in a carrier-phase differential (also known as real-time kinematic) mode. The base station is installed on the roof of one of the tallest buildings on our campus. It provides differential corrections via a radio link and over the network.
- an integrated HMR-3000 module consisting of a digital compass and a 2-axis tilt sensor
- an 11Mb/s IEEE 802.11b wireless network for continuous connectivity with remote hosts during autonomous operations. Numerous base stations are being installed on campus to extend the range of network connectivity.
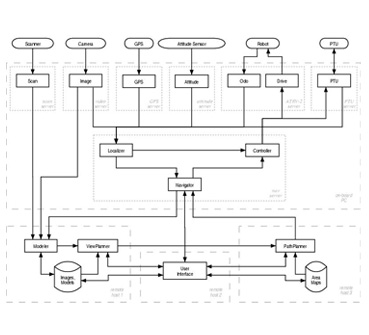
Software Architecture
- We have designed a distributed
object-oriented software architecture that facilitates the coordination of
the various components of the system. It is based on Mobility -- a robot
integration software framework developed by iRobot -- and makes heavy use of
CORBA.
The main building blocks are concurrently executing distributed software components. Components can communicate (via IPC) with one another within the same process, across processes and even across physical hosts. Components performing related tasks are grouped into servers. A server is a multi-threaded program that handles an entire aspect of the system, such as navigation control or robot interfacing. Each server has a well-defined interface that allows clients to send commands, check its status or obtain data.
The hardware is accessed and controlled by seven servers. A designated server, called NavServer builds on top of the hardware servers and provides localization and motion control services as well as a higher-level interface to the robot from remote hosts.
Components that are too computationally intense (e.g the modeling components) or require user interaction (e.g the user interface) reside on remote hosts and communicate with the robot over the wireless network link.
Localization
- Our localization system system employs two methods. The
first method uses odometry, the digital compass/pan-tilt module and the
global positioning sensor for localization in open space. An extended Kalman
filter integrates the sensor data and keeps track of the uncertainty
associated with it. When the global positioning data is reliable, the method
is used as the only localization method. When the data deteriorates, the
method detects the increased uncertainty and seeks additional data by
invoking the second localization method.
The second method, called visual localization, is based on camera pose estimation. It is heavier computationally, but is only used when it is needed. When invoked, it stops the robot, chooses a nearby building to use and takes an image of it. The pose estimation is done by matching linear features in the image with a simple and compact model of the building. A database of the models is stored on the on-board computer. No environmental modifications are required.
Protein Streak Seeding
-
Overview
The goal of the Protein Streak Seeding project is the creation of an innovative high-throughput (HTP) microrobotic system for a protein crystallography task called streak seeding. The system uses visual feedback from a camera mounted on a microscope to control a micromanipulator which has the mounting tool attached as its end-effector. For use with our robotic system, we have developed unique new tools, called miscroshovels, which are designed to address certain limitations of the traditionally used by crystallographers whiskers, bristles, or other kinds of hair.
Task Description
Streak seeding is useful when the initial crystallization experiments yield crystals which are too small (less than 40um in size) and/or of low quality and can not be used for structure determination. To obtain higher quality crystals, a new reaction is setup like the original one, however, before incubation, small fragments of the initially obtained crystals are transferred to the new protein-reagent mixture to bootstrap the crystallization process. This crystal fragment transfer process is called streak seeding.
The task of streak seeding consists of three steps (Fig.2). First, the tool to be used is washed in clean water to remove any residue. Second, the tool is used to touch and probe the existing crystals thus breaking them up into fragments and picking some up. Third, the tool is streaked through the fresh mixture, which deposits some of the fragments in it. For this to work, the tool has to have the necessary properties to be able to break up, retain and release crystal fragments, thus the material it is made of is very important factor in for the efficiency of the procedure. Traditionally, various types of hair, bristles, whiskers or horse tail have been used. CARESS: A Streak Seeding Robot
-
Based on earlier development efforts using our generic micro-robotic system for protein crystal manipulation, we have built a specialized streak seeding robot called CARESS. CARESS --- an acronym for Columbia [University's] Automated Robotic Environment for Streak Seeding, --- employs an innovative approach to protein streak seeding which utilizes our own custom tools, called microshovels, designed and fabricated using MEMS technology.
CARESS uses visual feedback from a camera mounted on a microscope to control a micromanipulator which has the mounting tool attached as its end-effector. All sensors and actuators are connected to a personal computer and controlled by an application running on it. The software is responsible for processing the visual stream from the camera using computer vision techniques to pinpoint the location of the objects of interest in the workspace, and for controlling the actuators accordingly. The user interacts with the application via a graphical interface to set the system up, execute tasks and view data.
The robot is designed to work with the hanging drop crystallization method, seeding from source crystals on a 21mm square coverslip to destination drops on a coversheet for a 96-well plate. The user sets up the system by placing on the stage the coverslip with the protein crystals, the coversheet of the 96-well plate with the target protein droplets, and a microbridge with water used for cleaning the seeding tool. Then the system is started and it performs the seeding autonomously. At top speed, one 96-well plate can be seeded in 5-6 minutes. The video in the side panel shows CARESS in operation. 
Streak Seeded Crystals

CARESS
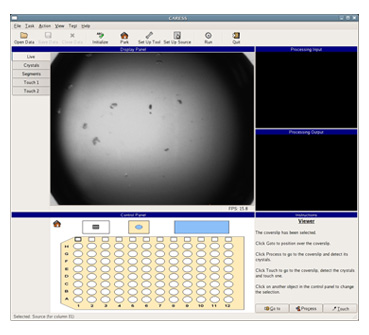
User Interface
Protein Crystal Mounting
-
Overview
The Protein Crystal Mounting project addresses the need in the Protein Crystallography community for high-throughput (HTP) equipment which will help improve the execution of a specialized task, called crystal mounting. The goal of this project is to produce a microrobotic system capable of performing the task autonomously, quickly and robustly. We have built a robotic system for crystal mounting which relies on visual feedback from a camera looking through a microscope to control a micromanipulator with the tool used for mounting attached as its end-effector.
Task Description
The task begins by placing a coverslip (usually a 21mm x 21mm square plastic slide, such as the ones used for 24-well Linbro plates) containing a droplet with protein crystals is placed under the microscope. The technician, looking through the microscope, uses a tool to catch and pick up the selected target crystal. The crystal is then quickly cryoprotected, frozen and stored for future data collection on an X-ray beamline.
The most-commonly used tool for mounting is the cryogenic loop (e.g. ones made by Hampton Research) though glass capillaries are also used. Recently, newly developed tools have been introduced, such as the micromounts manufactured by MiTeGen and our own microshovels.
The task is currently performed by skilled technicians. Mounting a crystal in a loop manually requires time, patience and excellent motor skills. Accuracy and speed are critical as the crystals are fragile and very sensitive to environmental changes. Dehydration quickly leads to crystal quality degradation. The video in the side panel is an example of what the task entails --- the loop in this video was installed on a micropositioner which was teleoperated. In reality, the task may be further complicated by the limited time for operation, "skins" forming on the surface of the droplet and crystals adhering to the coverslip.
Crystal mounting is a term that has been used to refer to both the task of picking up a protein crystal (a.k.a crystal harvesting) and the task of placing the tool with the crystal already on it on the beamline. In our work, we use the term to mean the former, and the latter we refer to as beamline mounting to avoid confusion System Design And Operation
- We have designed and assembled a microrobotic system for protein crystal manipulation, which we use for our research and experiments. An earlier version of the system successfully demonstrated the use of our microshovels for autonomous mounting. The current implementation relies on a two-stage approach, where one tool (a glass pipette) is used to pick up the crystal from the incubation drop and transfer it to another tool (a micromount or a microshovel), which holds the crystal during X-ray data collection.

A crystal mounted on a microshovel
- Crystal mounting is simply described as the transfer of a selected protein crystal from its growth solution into a suitable mounting tool for data collection on a synchrotron.

Crystal Mounting Setup
- The crystal mounting procedure starts with the placement of the necessary tools and objects in the work space. First, a microbridge with cryoprotector is placed at its designated location on the tray. Next, a micromount is installed on the fixture to the right and is positioned adequately so it is immersed in the cryprotector at an angle of approximately 45 degrees and is ready to receive the crystal. Finally, the user places a coverslip with the droplet containing the protein crystals on the microscope tray such that they are in the field of view.
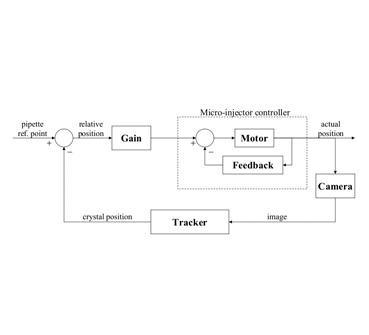
Control System Block Diagram
- The user starts the program and specifies which crystal (among the possibly many in the drop) is to be mounted. After that, the system proceeds autonomously: It immerses the pipette into the drop, approaches the crystal, aspirates the crystal, transitions from the drop on the coverslip to the cryoprotector in the microbridge and deposits the crystal in the mounting tool. Some of these steps are performed in open-loop fashion because the system is calibrated for the locations and dimensions of the relevant objects and the system actuators meet the requirement for positioning accuracy. The aspiration of the crystal, however, is an example of a step that crucially depends on reliable sensory feedback. To determine the location of the crystal and detect when the crystal is inside the pipette, we use region trackers applied to the visual feed from the camera. A control loop tracks the motion of the crystal as it is drawn into the pipette and adjusts the suction applied by the microinjector accordingly until the crystal is safely inside. A block diagram of the control algorithm is shown in the above image.
Visually Servoed Robots
- Paul's specific interest in machine vision is to monitor a large assembly workcell (about the size of a classroom). He want to visually track objects like tools, workpieces and grippers as they move around in the workcell. Therefore they custom built a ceiling-mounted gantry and attached a pan-tilt unit (PTU) and camera at the end-effector. The net result is a hybrid 5 degrees-of-freedom (DOF) robot that can position and orient the camera anywhere in the workspace. The hybrid robot servos the camera to keep the moving object centered in its field-of-view and at a desired image resolution.
Approach
-
Traditionally researchers attacked similar problems by measuring 3-D object pose from 2-D camera images. This requires a priori knowledge of the object geometry and hence researchers typically use CAD-based models or paint fiducial marks at specific locations on the object. The 3-D object pose measurements are then used with image and manipulator Jacobians to map velocity changes in the camera's image space to the robot's joint space. The net effect is that the robot servos the camera to regulate a desired camera-to-object pose constraint.
The caveat of such a regulation technique is that the robot's motors may not have sufficient bandwidth (torque capabilities) to maintain such a constraint. Our gantry is slow because of its heavy linkages. Failure to accelerate the camera fast enough will result in loss of visual contact. Furthermore, abrupt accelerations generate endpoint vibrations which effect image acquisition. By contrast, the PTU is lightweight and fast and can quickly rotate the camera to maintain visual contact. The net effect is that tracking performance depends on which DOF are invoked in the tracking task.
My approach to the tracking problem was to design a control law that defines a joint coupling between the PTU and gantry. This idea came from casually observing human tracking behavior. People also have joints (eyes, neck, torso) of varying bandwidths and kinematic range. We synergize all of our DOF when tracking a moving object and we don't need a priori object geometry knowledge. One also notices that the eyes and neck tend to pan in the same direction as we follow an object's motion trajectory. This behavior suggests an underlying kinematic joint coupling. Implementation
- Traditional approaches rely exclusively on image data. By contrast, most shop floor robots only use kinematic joint encoder data. A joint coupling can be achieved by combining both image and kinematic data. Image data is used to control pan and tilt DOFs to keep the target centered in the camera's field-of-view. The resulting kinematic angle data is used by the gantry to transport the camera in the direction of pan and/or tilt. By defining such a joint coupling in the underlying control law we mimic the synergistic human tracking behavior mentioned previously. The net effect of partitioning the DOFs in this manner is a tracking system that (1) does not need a CAD-based model; (2) can quickly track targets by taking advantage of the PTU's fast motor bandwidth; (3) can transport the camera anywhere in the workcell by taking advantage of the gantry's large kinematic range.
Results
-
Our assembly workcell includes an industrial Puma robot mounted with a Toshiba multi-purpose gripper to pick up tools and workpieces. We like to visually track this gripper as it moves in the workcell.
A single sum-of-squared differences (SSD) tracker was used to monitor the image position of the hand in the camera. This text-book image processing technique uses correlation to match blocks of pixels from one image frame to the next yielding real-time (30 frames/sec) results.
The gripper moves in a triangular trajectory; its position changes vertically, horizontally and in depth. A partitioned joint-coupling was defined between the tilt and vertical gantry DOF, and the pan and horizontal gantry DOF. SSD scale data was used to servo the remaining gantry DOF to maintain a desired image resolution (i.e. depth). The results were videotaped by both a handheld camera and the gantry-PTU camera Impact
-
The gripper speed ranged from 6 to 20 cm/s and was effectively tracked by the partitioned gantry-PTU system. By contrast, a traditional regulator was implemented by failed at gripper speeds greater than 2 cm/s due to the limited gantry motor bandwidth. The net effect is that the partitioned system can track faster moving objects, maintain image resolution, and does not a priori knowledge of object geometry.
By using a single SSD tracker a wide range of geometrically complex objects can be tracked using partitioning. For example, the system can track a person walking around the workcell. Grasping and Sensor Fusion
-
Grasping arbitrary objects with robotic hands remains a difficult task with many open research problems. Most robotic hands are either sensorless or lack the ability to report accurate position and force information relating to contact.
By fusing finger joint encoder data, tactile sensor data, strain gage readings and vision, we can increase the capabilities of a robotic hand for grasping and manipulation tasks. The experimental hand we are using is the Barrett Hand (left photo), which is a three-fingered, four DOF hand.
The hand is covered with tactile sensors which are used to localize contacts on the surface of the hand, as well as determine contact forces.
Impact
This model gives a deterministic measure of the deflection as a function of position along the finger. This information was then fused with image data from a tripod-mounted camera, and tactile sensor readings to augment grasp configuration. Experiments in using the hand to screw a canistor lid were successfully accomplished. Stewart Platform and Electrohydraulic Servovalve Control
-
A Stewart platform (left) is a 6 degree-of-freedom mechanism that is commonly used in flight simulators. The payload rests of the top platform and the linkages extend to yield yaw, pitch, roll orientations as well as vertical, sway and heave positions. My interests in the Stewart Platform were in designing a ship motion simulator (SMS) control system for the Korean Agency of Defense Development. The end-goal of the project was to mount an automatic firing mechanism on high-speed gunboats.
The SMS linkages are electrohydraulic. The platform positioning accuracy depends on operating and ambient factors such as temperature and fluid viscosity. Thus I designed a model reference adaptive controller (MRAC) to compensate for fluctuations in these factors. Preamble
-
Typically there are two approaches to digital control design. One approach is to use an analog model in the Laplace s-domain and then discretize using a zero-order-hold (ZOH). Another approach is to use a z-domain digital model from the very beginning of the design stage.
Both approaches have their advantages and disadvantages. Analog modeling gives the designer a better understanding of the real-world system, especially in terms of bandwidth and linearities. Digital modeling however readily lends itself to computer implementation but obscures real-world system understanding. This is in part due to the nature of the z-transform.
Intuitively one would think that as the sampling time approaches zero (i.e. a very fast sampling frequency) the discrete model should approach the form of the analog model. However the z-transform and ZOH does not yield this. In fact, at fast sampling frequencies, the discrete model will be non-minimum phase, that is, the discrete zeros will lie outside the unit circle. Since many controllers, including the MRAC rely on pole-zero cancellation, non-minimum phase must be eliminated to avoid instability. A stable control law thus requires using a large sampling time which leads to a loss in measurement accuracy.
The non-minimum phase phenomena is a result of using a shift operator (i.e. the z-transform and ZOH). In fact, shift operators are the reason why analog and discrete versions of the same control law (e.g. optimal, adaptive) exist. Again, intuitively one would think the discrete version of a control law should equal the analog version when the sampling time is zero. Approach
- I used the Euler operator to design a digital controller take gives advantages of analog design insight. This operator is just as easy to use as the shift operator and is consistent with intuition. As the sampling time approaches zero, the discrete Euler model approaches its analog equivalent. If the analog model is minimum phase then so will the discrete model. In fact, all continuous-time techniques can be readily applied to the discrete Euler model. For the Euler operator, the region of stability is a circle centered at -1/T with radius 1/T. As the sampling time, T, approaches zero, this stability region is the same as the Laplace s-domain. By contrast, the shift operator's stability region is always the unit circle irregardless of sampling time size.
Implementation
-
Using the Euler operator I designed a MRAC to control the position of single electrohydraulic link of the 6-dof Stewart Platform. The sampling time was 25 ms (40 Hz) which would have led to non-minimum phase zeros if the shift operator was used. The control law was programmed in Pascal on a 386 PC and analog-to-digital board (in 1991).
For system identification, a fast Fourier transform (FFT) machine was used to acquire the servovalve's Bode plot. This resulted in a third order Laplace transfer function which was then discretized with the Euler operator.
A model of the servovalve, with desired performance characteristics, was then designed for the adaptive strategy. This model was nominalized for ideal ambient and operating factors. The input was fed into both this model and the actual servovalve and outputs were compared. The output differences define an error which the adaptive strategy minimizes to generate a compensated input.
To demonstrate the MRAC's effectiveness the hydraulic supply pressure and fluid temperature were manually changed while in operation. Despite these changes, the electrohydraulic servovalve positioning error was negligible. Past Research Projects
Tracking and Grasping Moving Objects
-
Our laboratory was one of the first laboratories to exploit data parallelism in real-time computer vision. We have been responsible for the first set of low-level image processing algorithms written for the PIPE dataflow architecture and these algorithms have been a part of our technology transfer program to companies such as Siemens, Lockheed, FMC, and North American Philips. Machine vision has become an important research topic as the systems currently being developed are finally capable of processing rates to sustain real-time control from visual feedback.
We are interested in exploring the interplay of hand-eye coordination for dynamic grasping tasks where objects to be grasped are moving. Coordination between an organism's sensing modalities and motor control system is a hallmark of intelligent behavior, and we are pursuing the goal of building an integrated sensing and actuation system that can operate in dynamic as opposed to static environments. The system we are building is a multi-sensor system that integrates work in real-time vision, robotic arm control and stable grasping of objects. Our first attempts at this have resulted in a system that can track and stably grasp a moving model train in real-time. (See figures and video below.)
The algorithms we have developed are quite general and applicable to a variety of complex robotic tasks that require visual feedback for arm and hand control. Currently, we are extending this work to tracking in a full 3-D space, and instituting 2 new control algorithms that employ multiple moving object detection and a wrist mounted camera for finer tracking and grasping. This work is important in showing 1) that the current level of computational devices for vision and real-time control are sufficient for dynamic tasks that include moving objects, 2) optic-flow is robust enough to be computed in real-time for stereo matching and 3) it can define strategies for robotic grasping with visual feedback that may be motivated by human arm movement studies. Active Uncalibrated Visual Servoing
-
Calibration methods are often difficult to understand, inconvenient to use in many robotic environments, and may require the minimization of several, complex, non-linear equations (which is not guaranteed to be numerically robust or stable). Moreover, calibrations are typically only accurate in a small subspace of the workspace; accuracy degenerates quickly as the calibration area is left. This can pose a real problem for an active, moving camera system. In our case, using an active vision system, it is not feasible to recalibrate each time the system moves. What is needed is an online method of calibration that updates the relationships between the imaging and actuation systems. We have developed a new set of algorithms that can perform precise alignment and positioning without the need for calibration. By extracting control information directly from the image, we free our technique from the errors normally associated with a fixed calibration. We attach a camera system to a robot such that the camera system and the robot's gripper rotate simultaneously. As the camera system rotates about the gripper's rotational axis, the circular path traced out by a point-like feature projects to an elliptical path in image space. We gather the projected feature points over part of a rotation and fit the gathered data to an ellipse. The distance from the rotational axis to the feature point in world space is proportional to the size of the generated ellipse. As the rotational axis gets closer to the feature, the feature's projected path will form smaller and smaller ellipses. When the rotational axis is directly above the object, the trajectory degenerates from an ellipse to a single point.
We have demonstrated the efficacy of the algorithm on the peg-in-hole problem. A camera is mounted off to the side of the end-effector of the robot. A peg, which is to be inserted in a hole on the block, is aligned with the rotational axis of the end effector see figure 1. The algorithm uses an approximation to the Image Jacobian to control the movement of the robot. The components of the Jacobian J are dependent on the robot parameters, the transformation between the camera system and the robot system, and the camera system parameters. We calculate the Image Jacobian by making two moves in world space, observing the movements of the feature in image space. By empirically calculating the Image Jacobian at each new point (and throwing away the information from previous calculations), we can use the new estimates to move the robot to the correct alignment position even though we have not calibrated the two systems. Visually-Guided Grasping and Manipulation
-
Human experience provides an existence proof for the ability of vision to assist in grasping and manipulation tasks. Vision can provide rich knowledge about the spatial arrangements (i.e. geometry and topology) of objects to be manipulated as well as knowledge about the means of manipulation, which in our case are the fingers of a robotic hand. Our goal is to visually monitor and control the fingers of a robotic hand as it performs grasping and manipulation tasks. Our motivation for this is the general lack of accurate and fast feedback from most robotic hands. Many grippers lack sensing, particularly at the contact points with objects, and rely on open loop control to perform grasping and manipulation tasks. Vision is an inexpensive and effective method to provide the necessary feedback and monitoring for these tasks. Using a vision system, a simple uninstrumented gripper/hand can become a precision device capable of position and possibly even force control.
This research is aimed at using vision to provide the compliance and robustness which assembly operations require without the need for extensive analysis of the physics of grasping or a detailed knowledge of the environment to control a complicated grasping and manipulation task. Using vision, we gain an understanding of the spatial arrangement of objects in the environment without disturbing the environment, and can provide a means for providing robust feedback for a robot control loop. Our previous work has integrated both vision and touch for object recognition tasks. We would like to extend our object tracking system so that it can be used to provide visual feedback for locating the positions of fingers and objects to be manipulated, as well as the relative relationships between them. This visual analysis can be used to control grasping systems in a number of manipulation tasks where finger contact, object movement, and task completion need to be monitored and controlled. We also want to close a visual feedback loop around the forces from the Barrett hand system being proposed. By visually tracking the fingers and reading forces, we can accurately position the hand and monitor the status of grasps of objects. This research area is very rich, and relatively little work has been done in this area (a major impediment is acquiring an actual robotic hand since they are difficult to build and expensive to purchase). Model-Based Sensor Planning
-
The MVP system is a robust framework for planning sensor viewpoints. Given a CAD description of an object and its environment, a model of a vision sensor, plus a specification of the features to be viewed, MVP generates a camera location, orientation, and lens settings (focus-ring adjustment, focal length, aperture) which insure a robust view of the features. In this context, a robust view implies a view which is unobstructed, in focus, properly magnified, and well-centered within the field-of-view. In addition, MVP attempts to find a viewpoint with as much margin for error in all parameters as possible.
The next image shows a model of an object. Two edges on the inner cube are to be viewed. The following image shows the visibility volume -- from anywhere inside of this volume, the features can be seen. The last image shows the view from the viewpoint which the system computed.
We have added moving environment models to MVP and are exploring methods of extending MVP to plan viewpoints in a dynamic environment. The first approach, currently limited to the case of moving obstacles (the target, or features to view, are stationary), is to sweep the model of all moving objects along their trajectories and to plan around the swept volumes, as opposed to the actual objects. A temporal interval search is used in conjunction with the swept volumes to plan viewpoints which are valid for various intervals during the task. This approach has been implemented in simulation and experiments are being carried out in our robotics lab. The lab setup involves two robot arms, one carrying the camera, one moving about in the environment. The Dynamic MVP system plans viewpoints which guarantee robust views of some stationary target, despite the robot motion. The viewpoints are realized by the first robot while the second robot is moving about, performing its task. Autonomous Precision Manipulation
-
In our manipulation work, we investigate the requirements and implementation of precision tasks, in which ``precision tasks'' are defined as those in which the motions of grasped objects are caused by fingertip motions alone. The motivation for this work has been the development of strategies that will enable hands to perform precision tool tasks which require the control of interaction forces between the grasped object and the environment.
A set of primitive manipulations is defined, encompassing six fundamentally different techniques. Each manipulation defines a basic translation or rotation of an object with either circular or rectangular cross section and can be performed with a number of different grasp configurations. Taken together, the set of primitives enables the hand to rotate or translate objects in any direction in an object-centered frame. Defining basic strategies, an analog to motor control programs, simplifies the planning requirements of a robot system. Once a high-level planner has decided that a particular object motion is required, the action is performed autonomously. Manipulations are parametrized to cope with different task requirements, including grasp force, motion distance, and speed. It is assumed that the tasks are performed slowly enough to require quasistatic analysis, that the objects are rigid (though a precise object model is not required), and that force and position control are available. The elements of the tasks are: (1) a description of fingertip trajectories, (2) an analysis of the hand's workspace, (3) a method of maintaining grasp stability during manipulation, for which hybrid force/position control is used for task partitioning. Trajectories define the finger contact motions during manipulation. A hand's workspace is generally complex and does not admit a closed-form solution. For object manipulation, allowable fingertip trajectories for all contacts must be found simultaneously. A configuration-space analysis is performed that yields the maximum object motion distance for given sized objects, as well as the initial grasping positions and wrist positions in a global frame. This information is required to position the robot arm for maximum object manipulability, that is, to move it during the reach phase of a manipulation. Task partitioning, the specification of force- and position-controlled directions, simplifies the maintenance of grasp forces during manipulation and often yields a straightforward method to control the external object forces. Haptic Sensing
-
One area of research has been investigating the use of tactile information to recover 3-D object information. While acquisition of 3-D scene information has focused on either passive 2-D imaging methods (stereopsis, structure from motion etc.) or 3-D range sensing methods (structured lighting, laser scanning etc.), little work has been done using active touch sensing with a multi-fingered robotic hand to acquire scene descriptions, even though it is a well developed human capability. Touch sensing differs from other more passive sensing modalities such as vision in a number of ways. A multi-fingered robotic hand with touch sensors can probe, move, and change its environment. In addition, touch sensing generates far less data than vision methods; this is especially intriguing in light of psychological evidence that shows humans can recover shape and a number of other object attributes very reliably using touch alone.
In Allen and Michelman [7][5][4], shape recovery experiments are described using active strategies for global shape recovery, contour following, and surface normal computation. Our approach is to find gross object shape initially and then use a hypothesis and test method to generate more detailed information about an object, as discussed in Allen [1]. The first active strategy is grasping by containment, which is used to find an initial global estimate of shape which can then be further refined by more specific and localized sensing. Superquadrics are used as the global shape model. Once a superquadric has been fit to the initial grasp data, we have a strong hypothesis about an object's shape. Of particular importance are the shape parameters. The shape of an object can be inferred from these parameters and used to direct further exploration. For example, if the shape parameters indicate a rectangular object, then a strategy can trace out the plane and perform a least square fit of the trace data to test the surface's planarity. The second procedure we have developed is the planar surface strategy. After making contact with an object, the hand and arm move to the boundaries of the object's surface to map it out and determine its normal. The third exploratory procedure we have implemented is for surface contour following with a two-fingered grasp. This procedure allows us to determine an object's contour which has been shown to be a strong shape cue from previous vision research. During these experiments, the hand was equipped with Interlink force sensing resistive tactile sensors. The exploratory procedures were tested on a variety of objects-such as blocks, wedges, cylinders, bottles. The overall Utah/MIT hand system we have been using is described in Allen, Michelman and Roberts [3][2]. Object-space teleoperation
-
Teleoperation is a principle means of controlling robot hands for industry and for prosthetics. The traditional way of teleoperating a robot hand has been using a Dataglove or exoskeleton master: there is a direct mapping from the human hand to the robot hand. Generally, the finger positions of the human master are translated to the robot and visual or force feedback are returned from the robot to the master. (See Speeter et al. [1992], Pao and Speeter [1989], Burdea et al. [1992]). There are several difficulties with this approach:
Calibration: It is difficult to find a direct mapping from the human hand master to the robot. For example, Hong and Tan (Robotics &Automation, 1989) developed a complex three-step process each user must repeat.
The capabilities of robot hands are different from those of human hands. For example, the human hand can translate objects along only a single axis while a hand such as the Utah-MIT hand has the ability to translate objects in three Cartesian directions. Using a Dataglove thus reduces the manipulatory capabilities of the robot hand.
Autonomy: robot commands are displacements rather than functions. Without a high-level function, it is difficult to enhance a robot's autonomy. Furthermore, in situations in which there are long communication delays between the master and the robot (greater than 1 second), it is useful for the robot to perform certain functions autonomously (Bejczy and Kim [1990]).
High degree-of-freedom force feedback is still experimental and expensive.
In this type of ``manual control,'' the interface between the robot and the user primarily transfers data and performs coordinate transformations. We propose to increase the autonomy of the robot hand by shifting the control space from the joint positions to the space of the grasped object (see Michelman and Allen [10]). Rather than translate the motions of a master's fingers directly to motions of the robot hand, a simple, low degree-of-freedom input device, such as a joystick, controls the motions of the manipulated object directly. The motions of the manipulated object normally involve a single degree of freedom; they are two-dimensional translations and rotations. The system in turn computes the required finger trajectories to achieve the motion. The use of a low degree-of-freedom input device is appealing because it alleviates the problems cited above related to difficulty of calibration, the high input and sensor bandwidths required for full telemanipulation. In addition, increasing the autonomy of the robot allows it to perform tasks such as maintaining grasp forces and resisting external disturbances automatically. Low DOF input devices can include voice recognition systems, trackballs, Spaceballs (The Spaceball is a multi-function input device that senses forces and moments applied to it. It also has an array of software programmable buttons that can be assigned functions during a task.), myoelectric signals, and other devices used in industry and rehabilitation. The basis of the object-centered teleoperation system is set of primitive manipulations described above. Human Dexterity and Motor Control
- In parallel with work in robot dexterity, we are studying models of human dexterity and motor control in collaboration with Randall Flanagan (Teachers College, New York, N.Y.). This work focuses on several areas, primarily (1) studying grip force modulation under different conditions and object geometries and (2) analyzing the kinematics and grip forces on objects during human precision manipulation. There have been surprisingly few studies of human manipulation strategies as most attention has been directed to reach and grasping analyses. Our hope is to develop greater understanding of human manipulation through constrained psychophysical studies and motion analysis.
8-Degree of Freedom Robot
-
Overview
We are constructing an 8-degree of freedom robot. This will allow a wide range of arm positions for any given target position, thus giving a great flexibility of motion. Motion can be governed by additional constraints, such as distance to target position, or energy required to maintain position, for more realistic motion than conventional 6-degree of freedom systems, which have only a finite number of solutions for a target position.
The 8 degrees of freedom are achieved by combining a Unimation Puma arm (6 degrees of freedom) with a Directed Perception Pan/Tilt device (2 degrees of freedom). The pan/tilt device is mounted on the end of the Puma arm with a custom-built mount, and a CCD camera is mounted on the Pan/Tilt device. We are calibrating the device using a calibration plate, and following the procedure in the paper by Tsai and Lenz, "Overview of a Unified Calibration Trio for Robot Eye, Eye-to-Hand, and Hand Calibration using 3D Machine Vision."
The Directed Perception Pan/Tilt device gives us accuracy within 3 arc minutes, which allows us to precisely position the viewing angle, while it also gives us reasonable velocity and acceleration. It is controlled by hardware that automatically controls the acceleration curves, while allowing the programmer to set the velocity and acceleration parameters. Interactive Tutorials for Machine Vision
-
Overview
We are developing interactive tutorials for machine vision algorithms for use in an instructional lab setting. By "interactive," we mean that users can change the data sets and parameters of the algorithms, and even the operation of the algorithms themselves, in real-time to see the effect on the output.
One of the projects is called the Virtual Vision Lab and it provides a simulated laboratory environment with two Puma 560 Robots. One of the robots has a CCD video camera and the other one a pneumatic parallel gripper.
We are currently adding an Optical Flow module to the tutorial.