
- Offer Profile
- ALCOR has been established in
1998. The research activity focuses mainly on the perceptual inference
processes a cognitive robotics system should be able to activate.
We study and develop both methods of representation and methods of inference related to the perceptual process. Starting from early attention, we study many aspects of audio-visual salience, as induced by motion, actions, interactions. We are also interested in how classification of these different aspects of the concept of salience can lead to the recognition of different patterns of human behaviours, and in general to the recognition of how events unfold in the environment .
The Laboratory
- Our aim is to emphasize the recognition process as an effective inference process that can inform and determine the formation of knowledge about the environment, about how events are determined and induced, and about their spatio-temporal relations. We study this via different aspects of the recognition process, 3D reconstruction, people facial expression interpretation, motion interpretation, shape analysis, bottom-up attention in audio-visual scenes, natural images for visual localization, probabilistic and logical models of actions prediction. Most of our experiments use the Gaze machine, a device in progressive development.
Vision and Perception
Human Action Recognition
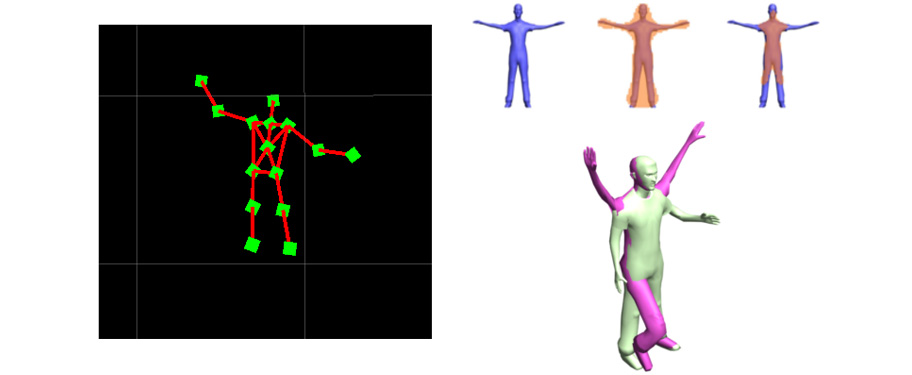
- Recognizing human actions is a prerequisite of
user-friendly, high-level human robot interaction. Furthermore it provides
the means for training an autonomous system through demonstration in order
to develop the skills that are necessary in performing an action.
To perceive human actions we employ sensors that range from omnidirectional cameras to depth sensors such as the Kinect, in order to build and utilize model-based representations of humans and at the same time identify the action context. Along the pipeline of the human action recognition process, our research is directed on non-rigid shape analysis and reconstruction based on level-set methods as well as pose-invariant shape matching.
X-SAR images classification

- In the last decades SAR images have arisen as one of
the most promising products of the remote sensing industry. On a satellite
platform, due to the moving antenna, to the frequency of the signal
(microwaves domain) and to the distance between source and target, a spatial
resolution less than one meter can be obtained. Those images are acquired
thanks to the use of a SAR sensor, that detects the radiation backscattered
from the object's surface. Nowadays the two most important satellites
missions equipped with a SAR sensor are the Italian (ASI) constellation of
small satellites named COSMO-SkyMed, and the satellite TerraSAR-X from
German aerospace center (DLR). All these satellites are on a sun-synchronous
orbit, at about 600 km above the earth surface, and uses a signal in the X
band (8-12 GHz). Acquisition mode can vary from: huge region ScanSAR to
SpotLight images. The microwaves domain guarantee high penetration through
clouds and atmosphere, and due to the fact that the SAR is an active system,
the acquired images are not depending on the illumination conditions. The
resulting images are graylevel-like images,and can be very helpful for
various purposes, as: environmental monitoring, coastline surveillance,
border control, and other topics related with the Ground Monitoring for
Environment and Security (GMES).
Our research deals with thousands of very high resolution images (COSMO-SkyMed X-SAR SpotLight images) of the Earth that are made available daily for all potential applications related to security and risks prevention. Despite their high azimuthal resolution, these images are, however, of difficult interpretation for the human eye, especially when precise understanding of a small scale region is needed, like urban neighborhood where several details of natural and human-made objects appear in the scene. The interpretation problem is, thus, to model the relation between each object in the scene and its backscattered signal, represented as image intensity values and witnessing how brightly the object or part of it reflected the specific wavelength.
In this field our research interest is based on defining a model to identify the relationship between objects as they appear in the images and the backscattering properties of each object, in order to derive an automatic interpretation of those images. The asset of our approach resides in the use of very high resolution images, with a pixel representing less than 1 square meter.
The presence of speckle noise can degrade the resulting image, especially over those areas where interactions between different parts of the radiated signal, during their travel, are more frequent (populated areas).
Due to the big experience of the Alcor Lab in the field of computer vision machine learning and pattern recognition, in a first stage we want to define a set of features that can best characterize different soil and land covers. So our efforts have focused on X-SAR SpotLight images of urban parks, as they can have a variegate set of land covers, and the speckle noise, due to different signal reflection, is usually lower than other areas.
Many algorithms have been developed in the computer vision community to enhance edges, corners, different textures, or to reproduce human visual system, or to compress images. But how can those features extractor be used for X-SAR images analysis and interpretation?
Our efforts so far have shown that some features, e.g. textural features, can best model water, and that a segmentation based on texture can be used to segment out water, with good results, also for very high resolution SpotLight X-SAR images. However from another point of view we saw that X-SAR tuned features descriptor must be designed to obtain a good classification, when the resolution becomes so high.
Planning and Cognitive Robotics
Task Switching
- In the real-world domains robots have to perform several activities
requiring a suitably designed cognitive control to select and coordinate the
operation of multiple tasks.
Cognitive control, in neuroscience studies, is the ability to establish the proper mapping between inputs, internal states and outputs neede to perform a given task. It is often analysed with the aid of the concept of inhibition, explaining how a subject in the presence of several stimuli responds selectively and is able to resist inappropriate urges. Congnitive control, as a general function, explains flexibly switching between tasks, when reconfiguration of memory and perception is required, by disengaging from previous goals or task sets.
Studies on cognitive control and mainly on human adaptive behaviours, investigated within the task-switching paradigm, have strongly influenced cognitive robotics architectures since the eighties. The approaches to model based executive robot control, vise runtime systems managing backward inhibition via real-time selection, execution and actions guiding, by hacking behaviours. This model-based view postulates the existence of a declarative (symbolic) model of the executive which can be used by the cognitive control to switch between processes within a reactive control loop.
In this context, the flexible temporal planning approach proposed by the planning community, has shown a strong practical impact in real world applications based on deliberation and execution integration. These approaches amalgamate planning, scheduling and resource optimisation for managing all the competing activities involved in many robot tasks. The flexible temporal planning approach, underpinning temporal constraint networks, provides a good model for behaviours interaction and temporal switching between different events and processes.
On the other hand, from a different perspective, high level executive control has been introduced in the qualitative Cognitive Robotics1 community, within the realm of theories of actions and change, such as the Situation Calculus, Fluent Calculus, Event Calculus, the Action language and their built-in agents programming languages such as the Golog family. In the theory of action and change framework the problem of executive control has been regarded mainly in terms of action properties, their effects on the world (e.g. the frame problem) and the agents ability to decide on a successful action sequence basing on its desire, intentions and knowledge.
Nonetheless reactive behaviours have been considered from the view point of the interleaving properties of the agents actions and external exogenous actions, induced by nature.
Real world robot applications are increasingly concerned not just (and not only) with properties of actions but also with the system reaction to a huge amount of stimuli, requiring to handle response timing. Therefore, the need to negotiate the multiplicity of reactions in tasks switching (for vision, localisation, manipulation, exploration, etc.) is bearing a different perspective on action theories.
An example is the increasing emphasis on agents programming languages or on multiple forms of interactions leading to the extraordinary explosion of multi-agent systems. Indeed, the control of many sources of information, incoming from the environment, likewise arbitration of resource allocation for perceptual-motor and selection processes, had become the core challenge in actions and behaviours modelling.
The complexity of executive control under the view of adaptive, flexible and switching behaviours, in our opinion, requires the design of a grounded and interpretative framework that can be accomplished only within a coherent and strong qualitative model of action, perception and interaction.
We want to extend the framework of the Situation Calculus, accomodating Allen temporal intervals, multiple timelines and concurrent situations, to represent heterogeneous, concurrent, and interleaving flexible behaviours, subject to switching-time criteria. This leads to a new integration paradigm in which multiple parallel timelines assimilate temporal constraints among the activities.
Multimodal HRI
- As a step toward the designing of a robot that can take part to a conversation we are developing a model of a conversation scenario, in which audio and visual cues are combined to perform multi-modal speaker recognition.

The robot actively follows a conversation

It focuses on the current speaker

multiple face detection and tracking
Robots and Equipment

GAZE MACHINE
- GAZE MACHINE is a wearable device that identifies the gaze scan path of the person wearing it, in the environment. It can be worn quite easily, so the subject wearing it can walk and go around in any light conditions, either indoor or outdoor.

VICON MX
- The Vicon MX system is quite simply the most advanced optical motion capture system available.The major components of a Vicon MX system are the cameras,the controlling hardware module, the software to analyze and present the data, and the host computer to run the software. Every Vicon MX system includes at least one MX Giganet to provide power and data communication with up to 10 cameras and other devices.

TALOS
- TALOS is a tracked mobile robot with two tracked bogies at the sides and four active tracked flippers placed at the front and rear, that endow it with increased mobility in rough terrain. It is equipped with active and passive sensors, namely, a rotating 2D SICK LMS-100 Laser, a Ladybug3 Omnidirectional camera, an inertia measurement unit (IMU) from Xsense, GPS and an on-board quad-core computer.

SECURO Agent (SHRIMP)
- Bluebotics ShrimpIII mechanical architecture provides the robot with an incredible mobility. It is able to easily move in a very challenging terrain, overcome vertical obstacles of twice its wheel size, and it can even climb stairs. The additional payload is composed by a light laptop, sensor for localization (inertial platform Crossbow) and for image acquisition (two firewire cameras PtGrey Flea), a pack of Li-Ion battery, communication (Bluetooth and Wireless 802.11a). All the additional payload is mounted on ad-hoc structure made of carbon fiber and plexiglass.

DORO Agent2 (Pioneer P3-AT)

DORO Agent1 (Pioneer 3DX)
- ActivMedia PIONEER 3-DX is an agile, versatile, intelligent mobile robotic platform able to carry loads robustly and to traverse sills, with high-performance management to provide power whenever it is needed. It is endowed with: a mobile head with a couple of stereo cameras provided by Allied Vison Technologies Marlin, an inertial platform Xsens MT9 for localization, eight sonars ring Polaroid. Other components are: a laptop Asus M3000N (centrino), a laser DISTO Leica, Odissey battery and correspondent power supply and a support structure. The software component installed on the laptop are: API ARIA and Saphira provided by ActiveMedia, Matlab (including Image Acquisition, Image Processing, Neural Network, Symbolic Math, Statistics, Optimization, Wavelet, Signal Processing toolbox), compiler C++, prolog ECLIPSE framework, PROLOG interpreter, Java. The value of the robot includes purposely developed software for localization, map reconstruction, communication and planning, navigation and recognition.
Computer Graphics
Computer Graphics
- Computer animation, physically-based simulation, GPGPU,
virtual characters animation
We research in the area of physically-based simulation as well as virtual characters animation synthesis, with emphasis on the application on entertainment and medical fields. In particular the research focuses on- the application of computational physical models to the simulation of soft
bodies and
- the design and implementation of parallel simulation algorithms and data structures suitable for the full exploitation of modern GPUs.
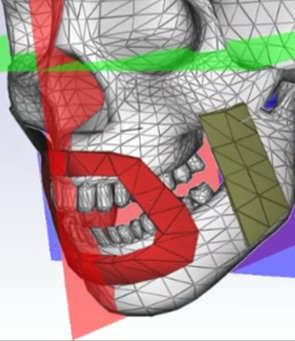
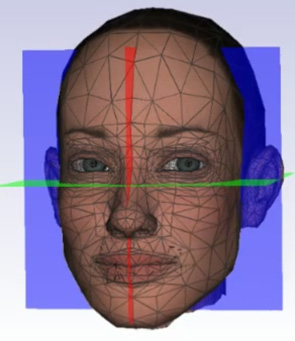
Computational Models for Animating 3D Virtual Faces
-
The simulation of facial movements is a difficult task because the complex and sophisticated structure of the human head involves the motion, deformation, and contact handling between bio-tissues that are viscoelastic, nonlinear, anisotropic, and structurally heterogeneous. This makes hard to formulate a mathematical model able to represent the biomechanical inner workings of the face. Nonetheless, high accuracy and precision are required because, as humans, we are used to observe and decode facial expressions from the moment we are born, and we are expert at easily detecting the smallest artifacts in a virtual facial animation.
We developed an integrated physically-based method which mimics the facial movements by reproducing the musculoskeletal structure of a human head and the interaction among the bony structure, the facial muscles and the skin. Experiments demonstrate that through this model it can be effectively synthesized realistic expressive facial animation on different input face models in real-time on consumer class platforms.

GPU-based soft bodies animation
- Consumer graphics adapters have evolved from petite units with very limited general applicability to high-power computational devices, which are very flexible in terms of their usage. Their computational power and memory bandwith undertook vast increases during the last years. Offering high-level-language support, recent graphics hardware is able to outperform CPU clusters in a wide range of applications. We developed a physics engine written in c++/CUDA and entirely relying on the parallel computation capabilities of the GPUs. However, instead of solving the physics constraints iteratively in a serial manner, in the pre-initialization phase the engine creates several different clusters of constraints which can be solved in parallel through a Red-Black Gauss-Siedel solver. In this way, the obtained performance is up to two orders of magnitude faster than the serial approach and we plan to apply such engine to different context, in particular to a surgical simulator and to automatic virtual character animation. We are also investigating on different algorithmic strategies for partitioning the constraint set in order to achieve a tunable workload balance across the multi-processors available on the graphics card

Multiple-legged Robots Simulation
- Robotic simulation is very important in developing
robotics applications, both for rapid prototyping of applications, behaviors,
scenarios, and for debugging purposes of many high-level tasks. Robot
simulators have been always used in developing complex applications, and the
choice of a simulator depends on the specific tasks we are interested in
simulating. Moreover, simulators are also very important for robotic
education: in fact, they are powerful teaching tools, allowing students to
develop and experiment typical robotic tasks at home, without requiring them
to use a real robot.